Guile now does delimited continuations.
Ahem! I say: Guile now does delimited continuations! Whoop whoop!
Practically speaking, this means that Guile implements prompt and abort, as described in Dorai Sitaram's 1993 paper, Handling Control. (Guile's abort is the operator that Sitaram calls control.)
I used to joke that all of this Guile compilation work was to bring Guile back into the 2000s, from being stuck in the 1990s. But delimited continuations are definitely a twenty-teens topic: besides PLT Scheme, I don't know of any other production language implementation that has delimited continuations as part of its core language. (Please correct my ignorance.) If this works out, and the implementation proves to be sufficiently bug-free, this is a great step forward not only for Guile but for the concept itself of delimited continuations.
Edit: Readers suggest that I add Scheme48, OCaml, and Scala to the list. Still, too few implementations for such a lovely construct.
Furthermore, I retrofitted Guile's existing catch and throw APIs, implementing them in terms of prompt and control, and providing compatible shims for Guile's C API.
Thanks again to Matthew Flatt for blazing the trail here.
rambling
So, for the benefit of those dozen or so people that will probably implement delimited continuations after me, here's a few strategies and pitfalls. For the rest of you, I recommend rancid wine.
First, I should make a disclaimer. Here, my focus is on a so-called "direct" implementation of delimited continuations; that is to say, I don't rely on a global continuation-passing style (CPS) transform of the source code.
There was recently an article posted to the Scheme reddit about Femtolisp, a Lisp implementation by Jeff Benzason. I thought it was pretty neat. I was especially pleased that he decided to support shift and reset; but bummed when I found out that he did so by local CPS-transformation. So you couldn't reset from arbitrary functions.
A local CPS-rewrite strategy doesn't work very well, because prompts are fundamentally dynamic. There is something fundamentally dynamic about them, that they are part of the dynamic environment (like dynamic-wind). So to support that via CPS, you end up needing some kind of double- or triple-barrelled CPS, with abort continuations as well. I think? I think.
So for me, direct implementation means that you use the language's native stack representation, not requiring global or local transformations.
Also I should confess that I didn't glean anything from Gasbichler and Sperber's Final Shift paper; in all likelihood, again due to my ignorance. So if I say things that they've said better, well, stories have to be retold to live, and it won't hurt if I add my interpretation.
the seitan of the matter
So, Digresso Riddikulus: poof! Where were we? And what's up with this jack-in-the-box? Yes, direct implementations of delimited continuations.
Here's a C program:
int baz ();
int bar () { return baz (); }
int foo () { return bar (); }
int main () { return foo (); }
And here's a C stack:

Right! So you see that function calls are pushing frames on the stack.
When you're programming normally, you have a top-down view of the stack. It's like standing on a ladder and looking down -- you see the top rung clearly, but the rest is obscured by your toolbelt.
Laying out the frames flat like this allows us to talk instead about the whole future of this program -- what it's doing, and what it's going to do. The future of the program is known as its continuation -- a funny word, but I hope the meaning is clear in this context.
Now, consider a C program that calls into some hypothetical Scheme, assuming appropriate Scheme definitions of foo, bar, and baz:
int main () { return eval ("(foo)"); }
And the corresponding pixels:
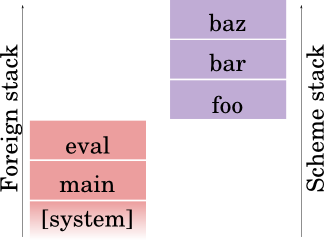
It should be clear that there are logically two stacks at work here. However they both correspond, in this case, to the same logical control-flow stack -- eval doesn't return until foo, bar, and baz have returned.
Also note that the "C" stack has been renamed the "foreign" stack, indicating that Scheme is actually where you want to be, and whatever is not in the Scheme world is heathen. This model maintains its truthiness regardless of the implementation strategy of the Scheme -- whether it reuses the C stack, or evaluates Scheme expressions on their own stack.
So! Delimited continuations, right? Let's try one. Here's some Scheme code that begins a prompt, and calls baz.
(% (baz) (lambda (k) k))
If baz returns normally, well that's the value; but if it aborts, the partial continuation will be saved, and returned. Verily, pixels:
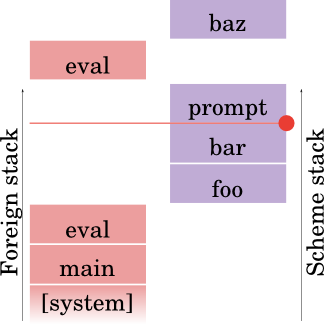
The red dot and line indicates that that position in the continuation has been saved, and if we abort, we'll abort back to that line. It's like grabbing a cherry from the tree, and then falling down a couple of rungs on the ladder. Yes? Yes.
Expanding the example with an implementation of baz, we have:
(define (baz) (abort) 3)
So, baz will abort to the nearest prompt, and if the abort comes back, it will return 3. Like this:
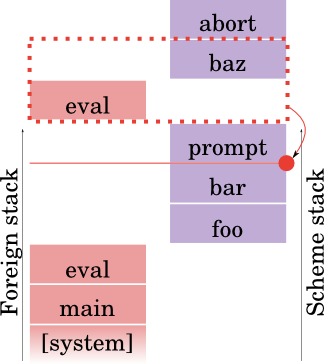
Abort itself needs to capture a partial continuation -- that part of the continuation that is delimited by prompt and abort. (That's why they're called delimited continuations.)
In practice, for the implementor, this has a number of fine points. The one I'll mention here is that you don't actually capture the prompt frame itself, or the presence of the prompt on the dynamic stack. I tried to indicate that in my drawings by making the red line disjoint from the red box. The red box is what's captured by the continuation.
See Dybvig's "A monadic framework for delimited continuations" for a more complete discussion of what to capture.
(define (qux) (+ (k) 38))
OK! Assume that we save away that partial continuation somewhere, let's say, in k. Now the evaluator ends up calling qux, which calls the partial continuation.
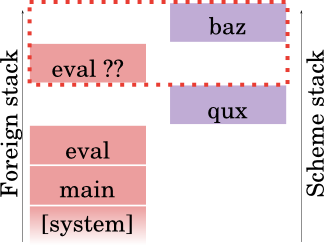
Calling the partial continuation in this context means splatting it on the stack, and then fixing things up so that it looks like we actually called baz from qux.
I'll get to the precise set of things you have to fix up, but let's pause a moment with these pixels, and make one thing clear: you can't splat foreign frames back on the stack. Maybe you can in some circumstances, but not in the general case.
The practical implication of this is twofold: one, delimited continuation support needs to be a core part of your language. You can't evaluate the "body" part of the prompt by recursing through a foreign function, for example.
The second (and deeper) implication is that if any intervening code does recurse through a foreign function, the resulting partial continuation cannot be reinstated.
One could simply error in this case, but it's more useful to allow nonlocal exits, and then error on an attempted re-entry.
So yes, things you need to fix up: obviously the frame pointer stack. The dynamic winds (and more generally, the dynamic environment). And, any captured prompts themselves. Consider:
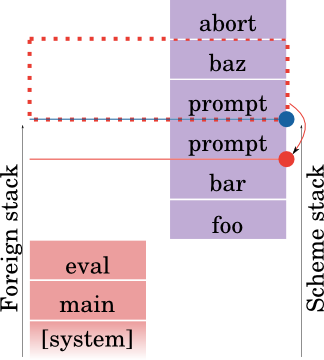
Here we see a prompt, which has a prompt inside it, which calls baz, which then aborts back to the first prompt. (You will need prompt tags for this.) Now, note: there are two horizontal lines here: two prompts active in the dynamic environment.
Let's see what happens when we reinstate the continuation, represented by the red dotted box:
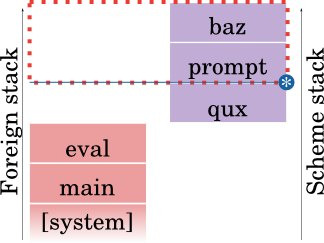
Here we see that the blue line corresponding to the captured prompt is in a different place (relative to the base of the stack). That's because when you reinstate a prompt, any captured prompts are logically made new: one must recapture their registers, both real (via setjmp) and virtual (in the case of a virtual machine) when rewinding the stack.
And that's all!
postre
Meanwhile, back at the ranch: while searching for the correct spelling of riddikulus, I stumbled upon a delightful interview with JK Rowling, in three parts. Enjoy!
