a new concurrent ml
Good morning all!
In my last article I talked about how we composed a lightweight "fibers" facility in Guile out of lower-level primitives. What we implemented there is enough to be useful, but it is missing an important aspect of concurrency: communication. Sure, being able to spawn off fibers is nice, but you have to be able to actually talk to them.
Fibers had just gotten to the state described above about a year ago as I caught a train from Geneva to Rome for Curry On 2016. Train rides are magnificent for organizing thoughts, and I was in dire need of clarity. I had tentatively settled on Go-style channels by the time I got there, but when I saw that Matthias Felleisen and Matthew Flatt there, I had to take advantage of the opportunity to ask them what they thought. Would they recommend Racket-like threads and channels? Had that been a good experience?
The answer that I got in return was a "yes, that's what you should do", but also a "you should look at Concurrent ML". Concurrent ML? What's that? I looked and was a bit skeptical. It seemed old and hoary and maybe channels were just as expressive. I looked more deeply into this issue and it seemed CML is a bit more expressive than just channels but damn, it looked complicated to implement.
I was wrong. This article shows that what you need to do to implement multi-core CML is actually the same as what you need to do to implement channels in a multi-core environment. By building CML first and channels and whatever later, you get more power for the same amount of work.
Note that this article has an associated talk! If video is your thing, see my Curry On 2017 talk here:
Or, watch on the youtube if the inline video above doesn't work; slides here as well.
on channels
Let's first have a crack at implementing channels. Before we begin, we should be a bit more explicit about what a channel is. My first hack in this area did the wrong thing: I was used to asynchronous queues, and I thought that's what a channel was. Besides ignorance, apparently that's what Erlang does; a process's inbox is an unbounded queue of messages with only very slight back-pressure.
But an asynchronous queue is not a channel, at least in its classic sense. As they were originally formulated in "Communicating Sequential Processes" by Tony Hoare, adopted into David May's occam, and from there into many other languages, channels are meeting-places. Processes meet at a channel to exchange values; whichever party arrives first has to wait for the other party to show up. The message that is handed off in a channel send/receive operation is never "owned" by the channel; it is either owned by a sender who is waiting at the meeting point for a receiver, or it's accepted by a receiver. After the transaction is complete, both parties continue on.
You'd think this is a fine detail, but meeting-place channels are strictly more expressive than buffered channels. I was actually called out for this because my first implementation of channels for Fibers had effectively a minimum buffer size of 1. In Go, whose channels are unbuffered by default, you can use a channel for RPC:
package main
func double(ch chan int) {
for { ch <- (<-ch * 2) }
}
func main() {
ch := make(chan int)
go double(ch)
ch <- 2
x := <-ch
print(x)
}
Here you see that the main function sent a value on ch, then immediately read a response from the same channel. If the channel were buffered, then we'd probably read the value we sent instead of the doubled value supplied by the double goroutine. I say "probably" because it's not deterministic! Likewise the double routine could read its responses as its inputs.
Anyway, the channels we are looking to build are meeting-place channels. If you are interested in the broader design questions, you might enjoy the incomplete history of language facilities for concurrency article I wrote late last year.
With that prelude out of the way, here's a first draft at the implementation of the "receive" operation on a channel.
(define (recv ch)
(match ch
(($ $channel recvq sendq)
(match (try-dequeue! sendq)
(#(value resume-sender)
(resume-sender)
value)
(#f
(suspend
(lambda (k)
(define (resume val)
(schedule (lambda () (k val)))
(enqueue! recvq resume))))))))
;; Note: this code has a race! Fixed later.
A channel is a record with two fields, its recvq and sendq. The receive queue (recvq) holds a FIFO queue of continuations that are waiting to receive values, and the send queue holds continuations that are waiting to send values, along with the value that they are sending. Both the recvq and the sendq are lockless queues.
To receive a value from a meeting-place channel, there are two possibilities: either there's a sender already there and waiting, or we have to wait for a sender. Those two cases are handled above, in that order. We use the suspend primitive from the last article to arrange for the fiber to wait; presumably the sender will resume us when they arrive later at the meeting-point.
an aside on lockless data structures
We'll go more deeply into the channel receive mechanics later, but first, a general question: what's the right way to implement a data structure that can be accessed and modified concurrently without locks? Though I am full of hubris, I don't have enough to answer this question definitively. I know many ways, but none that's optimal in all ways.
For what I needed in Fibers, I chose to err on the side of simplicity.
Some data in Fibers is never modified; this immutable data is safe to access concurrently from any code. This is the best, obviously :)
Some mutable data is only ever mutated from an "owner" core; it's safe to read without a lock from that owner core, and in Fibers we do not access this data from other cores. An example of this kind of data structure is the i/o map from file descriptors to continuations; it's core-local. I say "core-local" because in fibers we typically run one scheduler per core, with each core having a pinned POSIX thread; it's really thread-local but I don't want to use the word "thread" too much here as it's confusing.
Some mutable data needs to be read and written from many cores. An example of this is the recvq of a channel; many receivers and senders can be wanting to read and write there at once. The approach we take in Fibers is just to use immutable data stored inside an "atomic box". An atomic box holds a single value, and exposes operations to read, write, swap, and compare-and-swap (CAS) the value. To read a value, just fetch it from the box; you then have immutable data that you can analyze without locks. Having read a value, you can to compute a new state and use CAS on the atomic box to publish that change. If the CAS succeeds, then great; otherwise the state changed in the meantime, so you typically want to loop and try again.
Single-word CAS suffices for Guile when every value stored into an atomic box will be unique, a property that freshly-allocated objects have and of which GC ensures us an endless supply. Note that for this to work, the values can share structure internally but the outer reference has to be freshly allocated.
The combination of freshly-allocated data structures and atomic variables is a joy to use: no hassles about multi-word compare-and-swap or the ABA problem. Assuming your GC can keep up (Guile's does about 700 MB/s), it can be an effective strategy, and is certainly less error-prone than others.
back at the channel recv ranch
Now, the theme here is "growing a language": taking primitives and using them to compose more expressive abstractions. In that regard, sure, channel send and receive are nice, but what about select, which allows us to wait on any channel in a set of channels? How do we take what we have and built non-determinism on top?
I think we should begin by noting that select in Go for example isn't just about receiving messages. You can select on the first channel that can send, or between send and receive operations.
select {
case c <- x:
x, y = y, x+y
case <-quit:
return
}
As you can see, Go provides special syntax for select. Although in Guile we can of course provide macros, usually those macros expand out to a procedure call; the macro is sugar for a function. So we want select as a function. But because we need to be able to select over receiving and sending at the same time, the function needs to take some kind of annotation on what we are going to do with the channels:
(select (recv A) (send B v))
So what we do is to introduce the concept of an operation, which is simply data describing some event which may occur in the future. The arguments to select are now operations.
(select (recv-op A) (send-op B v))
Here recv-op is obviously a constructor for the channel-receive operation, and likewise for send-op. And actually, given that we've just made an abstraction over sending or receiving on a channel, we might as well make an abstraction over choosing the first available op among a set of operations. The implementation of select now creates such a choice-op, then performs it.
(define (select . ops) (perform (apply choice-op ops)))
But what we're missing here is the ability to know which operation actually happened. In Go, select's special syntax associates a clause of code with each sub-operation. In Scheme a clause of code is just a function, and so what we want to do is to be able to annotate an operation with a function that will get run if the operation succeeds.
So we define a (wrap-op op k), which makes an operation that itself annotates op, associating it with k. If op occurs, its result values will be passed to k. For example, if we make a fiber that tries to perform this operation:
(perform
(wrap-op
(recv-op A)
(lambda (v)
(string-append "hello, " v))))
If we send the string "world" on the channel A, then the result of this perform invocation will be "hello, world". Providing "wrapped" operations to select allows us to handle the various cases in separate, appropriate ways.
we just made concurrent ml
Hey, we just reinvented Concurrent ML! In his PLDI 1988 paper "Synchronous operations as first-class values", John Reppy proposes just this abstraction. I like to compare it to the relationship between an expression (exp) and wrapping that expression in a lambda ((lambda () exp)); evaluating an expression gives its value, and the expression just goes away, whereas evaluating a lambda gives a procedure that you can call in the future to evaluate the expression. You can call the lambda many times, or no times. In the same way, a channel-receive operation is an abstraction over receiving a value from a channel. You can perform that operation many times, once, or not at all.
Reppy consolidated this work in his PLDI 1991 paper, "CML: A higher-order concurrent language". Note that he uses the term "event" instead of "operation". To me the name "event" to apply to this abstraction never felt quite right; I guess I wrote too much code in the past against event loops. I see "events" as single instances in time and not an abstraction over the possibility of a, well, of an event. Indeed I wish I could refer to an instantiation of an operation as an event, but better not to muddy the waters. Likewise Reppy uses "synchronize" where I use "perform". As you like, really, it's still Concurrent ML; I just prefer to explain to my users using terms that make sense to me.
what's an op?
Let's return to that channel recv implementation. It had basically two parts: an optimistic part, where the operation could complete immediately, and a pessimistic part, where we had to wait for the other party to arrive. However, there was a race condition, as I noted in the comment. If a sender and a receiver concurrently arrive at a channel, it could be that they concurrently do the optimistic check, don't notice that the other is there, then they both suspend, waiting for each other to arrive: deadlock. To fix this for recv, we have to recheck the sendq after publishing our presence to the recvq.
I'll get to the details in a bit for channels, but it turns out that this is a general pattern. All kinds of ops have optimistic and pessimistic behavior.
(define (perform op)
(match op
(($ $op try block wrap)
(define (do-op)
;; Return a thunk that has result values.
(or optimistic
pessimistic)))
;; Return values, passed through wrap function.
((compose wrap do-op)))))
In the optimistic phase, the calling fiber will try to commit the operation directly. If that succeeds, then the calling fiber resumes any other fibers that are part of the transaction, and the calling fiber continues. In the pessimistic phase, we park the calling fiber, publish the fact that we're ready and waiting for the operation, then to resolve the race condition we have to try again to complete the operation. In either case we pass the result(s) through the wrap function.
Given that the pessimistic phase has to include a re-check for operation completability, the optimistic phase is purely an optimization. It's a good optimization that everyone will want to implement, but it's not strictly necessary. It's OK for a try function to always return #f.
As shown in the above function, an operation is a plain old data structure with three fields: a try, a block, and a wrap function. The optimistic behavior is implemented by the try function; the pessimistic side is partly implemented by perform, which handles the fiber suspension part, and by the operation's block function. The wrap function implements the wrap-op behavior described above, and is applied to the result(s) of a successful operation.
Now, it was about at this point that I was thinking "jeebs, this CML thing is complicated". I was both wrong and right -- there's some complication inherent in multicore lockless communication, yes, but I believe CML captures something close to the minimum, and certainly it's just as much work as with a direct implementation of channels. In that spirit, I continue on with the implementation of channel operations in Fibers.
channel receive operation
Here's an implementation of a try function for a channel.
(define (try-recv ch)
(match ch
(($ $channel recvq sendq)
(let ((q (atomic-ref sendq)))
(match q
(() #f)
((head . tail)
(match head
(#(val resume-sender state)
(match (CAS! state 'W 'S)
('W
(resume-sender (lambda () (values)))
(CAS! sendq q tail) ; *
(lambda () val))
(_ #f))))))))))
In Fibers, a try function either succeeds and returns a thunk, or fails and returns #f. For channel receive, we only succeed if there is a sender already in the queue: the sender has arrived, suspended itself, and published its availability. The state variable is an atomic box that holds the operation state, which initially starts as W and when complete is S. More on that in a minute. If the CAS! compare-and-swap operation managed to change the state from W to S, then the optimistic phase suceeded -- yay! We resume the sender with no values, take the value that the sender gave us, and keep on trucking, returning that value wrapped in a thunk.
Additionally the sender's entry on the sendq is now stale, as the operation is already complete; we try to pop it off the queue at the line indicated with *, but that could fail due to concurrent queue modification. In that case, no biggie, someone else will do the collect our garbage for us.
The pessimistic case is a bit more involved. It's the last bit of code though; almost done here! I express the pessimistic phase as a function of the operation's block function.
(define (pessimistic block)
;; For consistency with optimistic phase, result of
;; pessimistic phase is a thunk that "perform" will
;; apply.
(lambda ()
;; 1. Suspend the thread. Expect to be resumed
;; with a thunk, which we arrange to invoke directly.
((suspend
(lambda (k)
(define (resume values-thunk)
(schedule (lambda () (k values-thunk))))
;; 2. Make a fresh opstate.
(define state (make-atomic-box 'W))
;; 3. Call op's block function.
(block resume state))))))
So what about that state variable? Well basically, once we publish the fact that we're ready to perform an operation, fibers from other cores might concurrently try to complete our operation. We need for this perform invocation to complete at most once! So we introduce a state variable, the "opstate", held in an atomic box. It has three states:
W: "Waiting"; initial state
C: "Claimed"; temporary state
S: "Synched"; final state
There are four possible state transitions, of two kinds. Firstly there are the "local" transitions W->C, C->W, and C->S. These transitions may only ever occur as part of the "retry" phase a block function; notably, no remote fiber will cause these transitions on "our" state variable. Remote fibers can only make the W->S transition, committing an operation. The W->S transition can also be made locally of course.
Every time an operation is instantiated via the perform function, we make a new opstate. Operations themselves don't hold any state; only their instantiations do.
The need for the C state wasn't initially obvious to me, but after seeing the recv-op block function below, it will be clear to you I hope.
block functions
The block function itself has two jobs to do. Recall that it's called after the calling fiber was suspended, and is passed two arguments: a procedure that can be called to resume the fiber with some number of values, and the fresh opstate for this instantiation. The block function has two jobs: it needs to publish the resume function and the opstate to the channel's recvq, and then it needs to try again to receive. That's the "retry" phase I was mentioning before.
Retrying the recv can have three possible results:
If the retry succeeds, we resume the sender. We also have to resume the calling fiber, as it has been suspended already. In general, whatever code manages to commit an operation has to resume any fibers that were waiting on it to complete.
If the operation was already in the S state, that means some other party concurrently completed our operation on our behalf. In that case there's nothing to do; the other party resumed us already.
Otherwise if the operation couldn't proceed, then when the other party or parties arrive, they will be responsible for completing the operation and ultimately resuming our fiber in the future.
With that long prelude out of the way, here's the gnarlies!
(define (block-recv ch resume-recv recv-state)
(match ch
(($ $channel recvq sendq)
;; Publish -- now others can resume us!
(enqueue! recvq (vector resume-recv recv-state))
;; Try again to receive.
(let retry ()
(let ((q (atomic-ref sendq)))
(match q
((head . tail)
(match head
(#(val resume-send send-state)
(match (CAS! recv-state 'W 'C) ; Claim txn.
('W
(match (CAS! send-state 'W 'S)
('W ; Case (1): yay!
(atomic-set! recv-state 'S)
(CAS! sendq q tail) ; Maybe GC.
(resume-send (lambda () (values)))
(resume-recv (lambda () val)))
('C ; Conflict; retry.
(atomic-set! recv-state 'W)
(retry))
('S ; GC and retry.
(atomic-set! recv-state 'W)
(CAS! sendq q tail)
(retry))))
('S #f))))) ; Case (2): cool!
(() #f))))))) ; Case (3): we wait.
As we said, first we publish, then we retry. If there is a sender on the queue, we will try to complete their operation, but before we do that we have to prevent other fibers from completing ours; that's the purpose of going into the C state. If we manage to commit the sender's operation, then we commit ours too, going from C to S; otherwise we roll back to W. If the sender itself was in C then we had a conflict, and we spin to retry. We also try to GC off any completed operations from the sendq via unchecked CAS. If there's no sender on the queue, we just wait.
And that's it for the code! Thank you for suffering through this all. I only left off a few details: the try function can loop if sender is in the C state, and the block function needs to avoid a (choice-op (send-op A v) (recv-op A)) from sending v to itself. But because opstates are fresh allocations, we can know if a sender is actually ourself by comparing its opstate to ours (with eq?).
what about select?
I started about all this "op" business because I needed to annotate the arguments to select. Did I actually get anywhere? Good news, everyone: it turns out that select doesn't have to be a primitive!
Firstly, note that the choose-op try function just needs to run all try functions of sub-operations (possibly in random order), returning early if one succeeds. Pretty straightforward. And actually the story with the block function is the same: we just run the sub-operation block functions, knowing that the operation will commit at most one time. The only complication is plumbing through the respective wrap functions to all of the sub-operations, but of course that's the point of the wrap facility, so we pay the cost willingly.
(define (choice-op . ops)
(define (try)
(or-map
(match-lambda
(($ $op sub-try sub-block sub-wrap)
(define thunk (sub-try))
(and thunk (compose sub-wrap thunk))))
ops))
(define (block resume opstate)
(for-each
(match-lambda
(($ $op sub-try sub-block sub-wrap)
(define (wrapped-resume results-thunk)
(resume (compose sub-wrap results-thunk)))
(sub-block wrapped-resume opstate)))
ops))
(define wrap values)
(make-op try block wrap))
There are optimizations possible, for example to randomize the order of visiting the sub-operations for more less deterministic behavior, but this is really all there is.
concurrent ml is inevitable
As far as I understand things, the protocol to implement CML-style operations on channels in a lock-free environment are exactly the same as what's needed if you wrote out the recv function by hand, without abstracting it to a recv-op.
You still need the ability to park a fiber in the block function, and you still need to retry the operation after parking. Although try is just an optimization, it's an optimization that you'll want.
So given that the cost of parallel CML is necessary, you might as well get what you pay for and have your language expose the more expressive CML interface in addition to the more "standard" channel operations.
concurrent ml between pthreads and fibers
One really cool aspect about implementing CML is that the bit that suspends the current thread is isolated in the perform function. Of course if you're in a fiber, you suspend the current fiber as we have described above. But what if you're not? What if you want to use CML to communicate between POSIX threads? You can do that, just create a mutex/cond pair and pass a procedure that will signal the cond as the resume argument to the block function. It just works! The channels implementation doesn't need to know anything about pthreads, or even fibers for that matter.
In fact, you can actually use CML operations to communicate between fibers and full pthreads. This can be really useful if you need to run some truly blocking operation in a side pthread, but you want most of your program to be in fibers.
a meta-note for a meta-language
This implementation was based on the Parallel CML paper from Reppy et al, describing the protocol implemented in Manticore. Since then there's been a lot of development there; you should check out Manticore! I also hear that Reppy has a new version of his "Concurrent Programming in ML" book coming out soon (not sure though).
This work is in Fibers, a concurrency facility for Guile Scheme, built as a library. Check out the manual for full details. Relative to the Parallel CML paper, this work has a couple differences beyond the superficial operation/perform event/sync name change.
Most significantly, Reppy's CML operations have three phases: poll, do, and block. Fibers uses just two, as in a concurrent context it doesn't make sense to check-then-do. There is no do, only try :)
Additionally the Fibers channel implementation is lockless, with an atomic sendq and recvq. In contrast, Manticore uses a spinlock and hence needs to mask/unmask interrupts at times.
On the other hand, the Parallel CML paper included some model checking work, which Fibers doesn't have. It would be nice to have some more confidence on correctness!
but what about perf
Performance! Does it scale? Let's poke it. Here I'm going to try to isolate my tests to measure the overhead of communication of channels as implemented in terms of Parallel CML ops. I have more real benchmarks for Fibers on a web server workload where it does well, but here I am really trying to focus on CML.
My test system is a 2 x E5-2620v3, which is two sockets each having 6 2.6GHz cores, hyperthreads off, performance governor on all cores. This is a system we use for Snabb testing, so the first core on each socket handles interrupts and all others are reserved; Linux won't schedule anything on them. When you run a fibers system, it will spawn a thread per available core, then set the thread's affinity to that core. In these tests, I'll give benchmarks progressively more cores and see how they do with the workload.
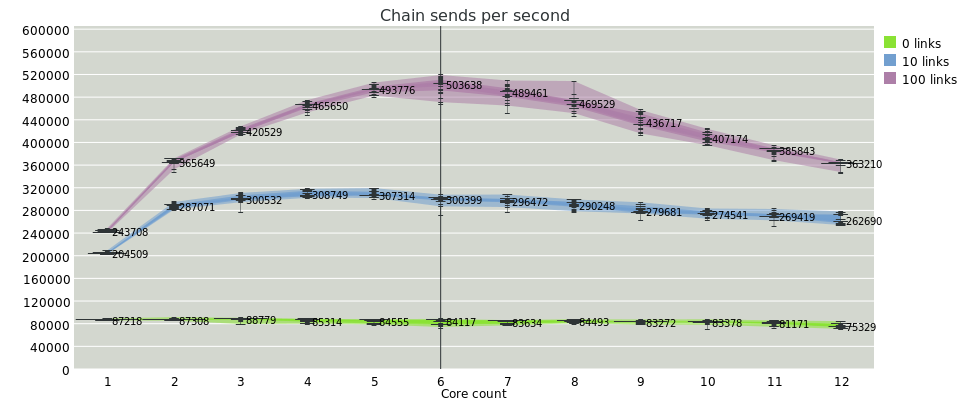
So this is a benchmark measuring total message sends per second on a chain of fibers communicating over channels. For 0 links, that means that there's just a sender and a receiver and no intermediate links. For 10 links, each message is relayed 10 times, for 11 total sends in the chain and 12 total fibers. For 0 links we expect pretty much no parallel speedup, and no slowdown, and that's what we see; but when we get to more links, we should expect more throughput. The fibers are allocated to cores at random (a randomized round-robin initial scheduling, then after that fibers have core affinity; though there is a limited work-stealing phase).
You would think that the 1-core case would be the same for all of them. Unfortunately it seems that currently there is a fixed cost for bouncing through epoll to pick up new I/O tasks, even though there are no I/O runnables in this test and the timeout is 0, so it will return immediately. It's definitely something to look into as it's a cost that all cores are paying.
Initially I expected a linear speedup but that's not what we're seeing. But then I thought about it and revised my expectations :) As we add more cores, we add more communication; we should see sublinear speedups as we have to do more cross-core wakeups and synchronizations. After all, we aren't measuring a nice parallelizable computational workload: we're measuring overhead.
On the other hand, the diminishing returns effect is pretty bad, and then we hit the NUMA cliff: as we cross from 6 to 7 cores, we start talking to the other CPU socket and everything goes to shit.
But here it's hard to isolate the test from three external factors, whose impact I don't understand: firstly, that Fibers itself has a significant wakeup cost for remote schedulers. I haven't measured contention on scheduler inboxes, but I suspect one issue is that when a remote scheduler has decided it has no runnables, it will sleep in epoll; and to wake it up we need to write on a socketpair. Guile can avoid that when there are lots of runnables and we see the remote scheduler isn't sleeping, but it's not perfect.
Secondly, Guile is a bytecode VM. I measured that Guile retires about 0.4 billion instructions per second per core on the test machine, whereas a 4 IPC native program will retire about 10 billion. There's overhead at various points, some of which will go away with native compilation in Guile but some might not for a while, given that Go (for example) has baked-in support for channels. So to what extent is it the protocol and to what extent the implementation overhead? I don't know.
Finally, and perhaps most importantly, we can't isolate this test from the garbage collector. Guile still uses the Boehm GC, which is just OK I think. It does have a nice parallel mark phase, but it uses POSIX signals to pause program threads instead of having those threads reach safepoints; and it's completely NUMA-unaware.
So, with all of those caveats mentioned, let's see a couple more graphs :) Firstly, similar to the previous one, here's total message send rate for N pairs of fibers that ping-pong their message back and forth. Core allocation was randomized round-robin.
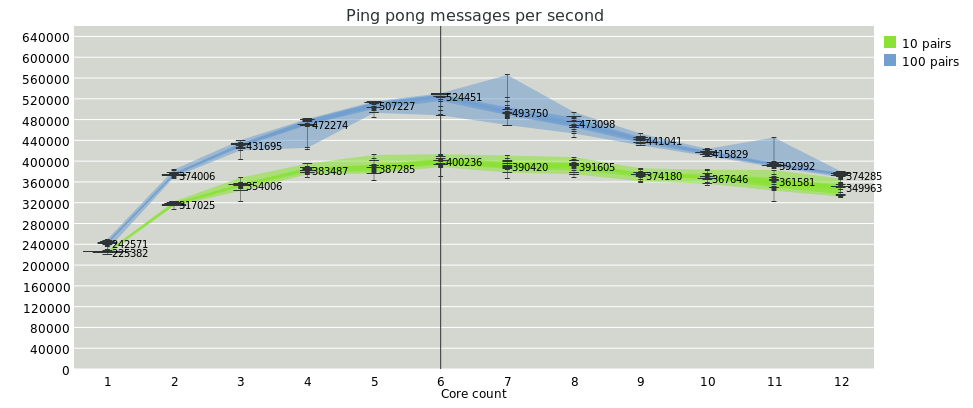
My conclusion here is that when more fibers are runnable per scheduler turn, the overhead of the epoll phase is less.
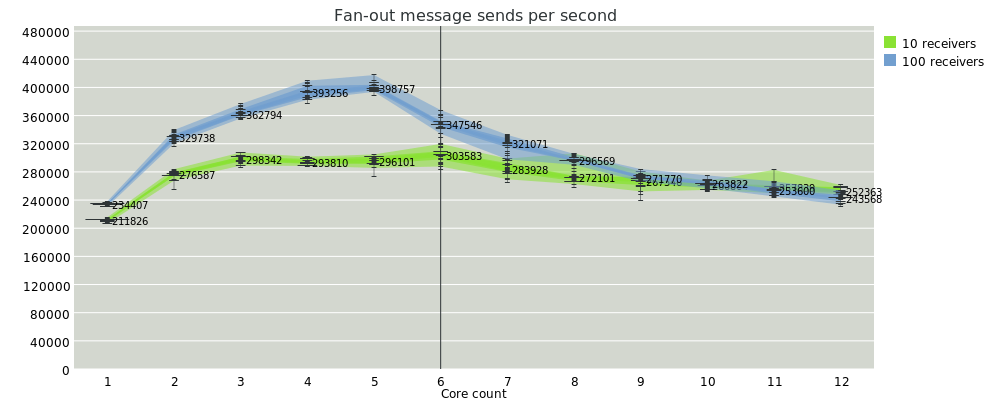
Here's a test where there's one fiber producer, and N fibers competing to consume the messages sent. Ultimately we expect that the rate will be limited on the producer side, but there's still a nice speedup.
Next is a pretty weak-sauce benchmark where we're computing diagonal lengths on an N-dimensional cube; the squares of the dimensions happen in parallel fibers, then one fiber collects those lengths, sums and makes a square root.
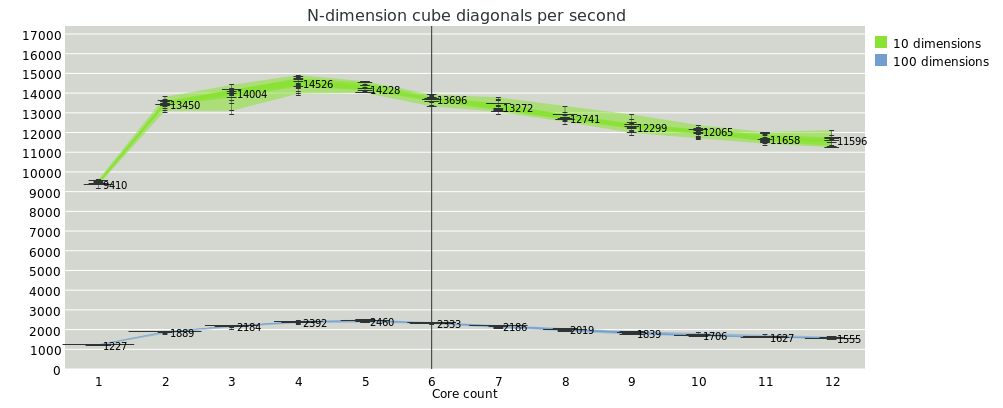
The workload on that one is just very low, and the serial components become a bottleneck quickly. I think I need to rework that test case.
Finally, there's a false sieve of Erastothenes, in which every time we find a prime, we add another fiber onto the sieve chain that filters out multiples of that prime.
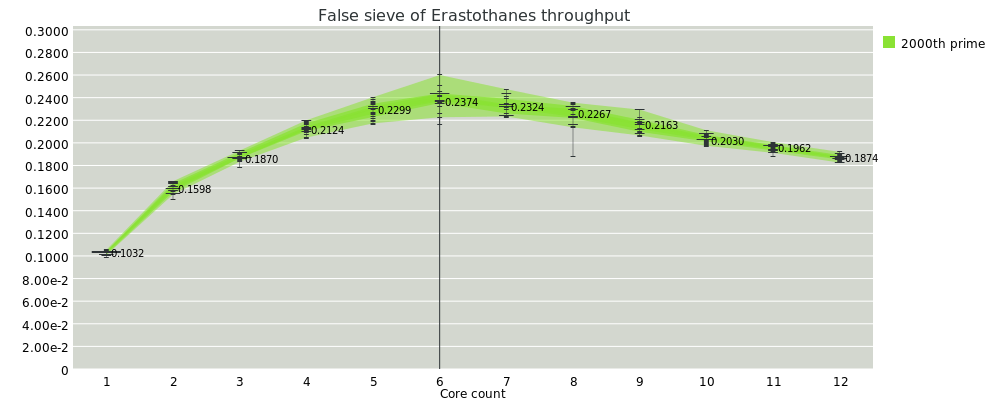
Even though the workload is really small, we still see speedups, which is somewhat satisfying. Still, on all of these, the NUMA cliff is something fierce.
For me what these benchmarks show is that there are still some bottlenecks to work on. We do OK in the handful-of-cores scenario, but the system as a whole doesn't really scale past that. On more real benchmarks with bigger workloads and proportionally much less communication, I get much more satisfactory results; but those tend to be I/O heavy anyway, so the bottleneck is elsewhere.
closing notes
There are other parts to CML events, namely guard functions and withNack functions. My understanding is that these are implementable in terms of this "primitive" CML as described here; that was a result of earlier work by Matthew Fluet. I haven't actually implemented these yet! A to-do item, truly.
There are other event types in CML systems of course! Besides being able to implement operations yourself, there are built-in condition variables (cvars), timeouts, thread join events, and so on. The Fibers manual mentions some of these, but it's an open set.
Finally and perhaps most significantly, Aaron Turon did some work a few years ago on "Reagents", a pattern library for composing parallel and concurrent operations, initially in Scala. It's claimed that Reagents generalizes CML. Is this the case? I am looking forward to finding out.
OK, that's it for this verrrrry long post :) I hope that you found that this made parallel CML seem a bit more approachable and interesting, whether as a language implementor, a library implementor, or a user. Comments and corrections welcome. Check out Fibers and give it a go!
4 responses
Comments are closed.
I've been waiting for this post for a while, but it was worth it! Thanks for the great walkthrough of your thought process and implementation decisions.
I wonder if you've looked at Haskell's Software Transactional Memory (STM). I think Clojure implements something similar. Simon Peyton Jones' paper "Composable memory transactions" is worth reading:
https://www.microsoft.com/en-us/research/wp-content/uploads/2005/01/2005-ppopp-composable.pdf
This is important if you want to share mutable data between threads.
Thank you for your great writeup!
If you want to look into STM, you can also get current information from the pypy devs, with some benchmarks: https://morepypy.blogspot.de/search/label/stm
They try to get that funded: http://pypy.org/tmdonate2.html
Here’s a talk about STM in pypy from 2 years ago: https://ep2015.europython.eu/conference/talks/the-gil-is-dead-pypy-stm → https://www.youtube.com/watch?v=e8wUiGDDVno
Thanks Andy, this is impressive work and a very neat implementation.
Looking at the scalability graphs, I'm reminded that when we discussed the downsides to bi-directional synchronisation, I think we mostly talked engineering concerns. Once you start bringing NUMA into the picture, there is a definite performance cost. If you can release a value onto a buffered queue and a later thread can acquire it, both threads can get useful work done in the meantime.
I've had a few experiences where moving away from bi-directional synchronisation has been good for performance, so I wonder if you got the chance to run the same benchmark in 8sync or so to compare the numbers?