V8 is faster than GCC
Do you like the linkbait title? Neither do I, but it is true in this case. Check it out.
After my last post, Benjamin noted that GCC would reduce my simple test to a mov rax, $10000000; ret sequence. Well yes, that's true, and GCC does do that: but only if GCC is able and allowed to do the inlining. So the equivalent of the test, for GCC, is to compile the g in a separate file:
unsigned int g (void) { return 1; }
Then in the main file, we have:
extern unsigned int g (void);
int main (int argc, char *argv) {
unsigned int i, ret = 0;
for (i = 0; i < NU; i++)
ret += g ();
return ret;
}
Here we replace N with the number of iterations we're interested in testing.
I decided to run such a test; the harness is here. I ran both GCC and V8 for the above program, for N from 20 to 231, and plotted the total time taken by V8 as compared to GCC.
Naturally this includes the GCC compile times, for which we expect GCC to lose at low iterations, but the question is, when does GCC start being faster than V8?
answer: never!
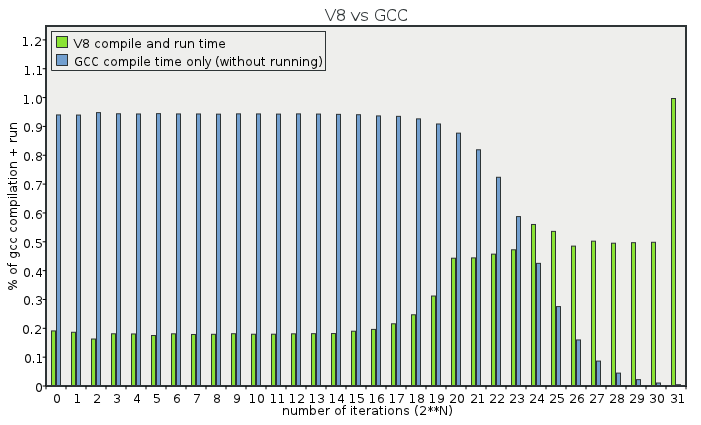
That's right, V8 is always faster than GCC, right up to the point at which its fixnums start failing. For the record, only the points on the right of the graph are really worth anything, as the ones on the left only run for a few milliseconds. Raw data here.
Why is V8 faster, even for significant iteration counts? Because it can inline hot function calls at runtime. It can see more than GCC can, and it takes advantage of it: but still preserving the dynamic characteristics of JavaScript. In this context the ELF symbol interposition rules that GCC has to deal with are not such a burden!
20 responses
Comments are closed.
Seems logical. GCC deals with the code only once, ant after it's done there is no room for improvement. V8 deals with the same code over and over and can improve optimization over time.
But...
You usually compile code with GCC only once. Noone compiles everything everytime he wants to use something. So, comparing compile+run time between V8 and GCC is not fair - GCC has much harder job to do to create good code, because it can't improve it over time.
Points well taken, Adam; but note that for significant workloads in GCC, the runtime is longer than the compile time, and so it is a win to do some adaptive compilation at runtime.
That said, I am working on an AOT compiler for Guile, not a JIT. I'll write more about why I'm doing that sometime soon.
(Specifically: that for more than 2^23 iterations in this case, GCC spends more time running the code than compiling it.)
Use the -flto compiler flag for gcc please!!! (And correct the title to: GCC compiled binaries are faster than V8)
Did you just benchmark a JIT compiler vs a static compiler? *stabs self*
I thought it would be obvious, but I'll say it anyway: LTO is a good step. But besides being quite new, can't help users of a shared library.
Nice piece. It's worth considering that a lot of code is never going to run enough times for the time saved running the code to outweigh the time spent compiling the code, especially if you take iterative development into consideration.
In essence, one takeaway message is that — as usual — premature optimization is the root of all evil, including using a low level language when a short level language will do.
Taking this at face value:
GCC has a lot of overhead associated with supporting everything under the sun, including most static languages and most possible optimizations.
V8 would have to support all dynamic languages (like ruby, perl, etc) in order to make this more comparable. In fact, V8 is specific to Javascript.
To be fair, throw TCC or clang into the mix and see how a more minimal C-only compiler will compare.
Put the code on 1 million devices.
How is gcc compile time significant now?
Facepalm.
Nice troll. Attempt.
You say:
"Well yes, that's true, and GCC does do that: but only if GCC is able and allowed to do the inlining."
and then:
"Because it can inline hot function calls at runtime. It can see more than GCC can, and it takes advantage of it: but still preserving the dynamic characteristics of JavaScript."
As much as I would like to believe your test, you're comparing the V8 and GCC under unequal circunstances, why is V8 allowed to inline if you forbid GCC to do the same?
Does anyone actually care if such a simple loop can be optimised better by V8? How about comparing some more practical code e.g. sorting linked lists or doing some crypto?
First off, the code you are running is not indicative of anything that would actually happen in the real world.
Secondly, you are binding gcc in multiple ways and then letting V8 run optimally. By your own writing gcc compiles the entire routine to a SINGLE OP-CODE that executes in a SINGLE CLOCK CYCLE but that doesn't support your argument so you force gcc to do it in a way that is less than optimal to support your original assertion.
Third, why are you including compile time in the benchmark? For any significant number of iterations compile time is moot.
What you've just written is one of the most contrived benchmarks I have ever read. At no point in your rambling, incoherent argument were you even close to anything that could be considered an objective comparison. Everyone in this room is now dumber for having read it. I award you no points, and may God have mercy on your soul.
Could you please post the raw timings? I'm actually curious about the Javascript run times for higher order N.
I hear what the compiled geeks are saying, and they're correct, but consider that V8 is Google's first stab at this. The point that V8 can have greater insight into any given code than gcc must be given weight; once could imagine a V9 that, when seeing excessive execution times, does a actual reanalysis and compile of the section of Javascript most beneficial, giving you the best of JIT and compiled languages in one package.
Um, OK! I'm not sure why this pushed a bunch of people's buttons. I can only assume that I didn't explain myself clearly enough.
There was a concern that GCC's compile-once, run-many-times characteristic is somehow being disrespected (Adam, Matthias, Brennan). That's not the case at all -- as you can see at significant iteration counts, compile time is a small fraction of run time (30ms versus about 2500ms). The fact is that V8's compiled result is simply better.
I included GCC's compile time to be fair to V8 at low numbers of iterations, but expected GCC to be faster once compile time was a small fraction of run time (which, as no one noted, already included starting V8 from scratch each time).
Folks seem to feel a need to evince GCC as a better compiler (Tobias, Christopher, Matthias, Eki). Of course it's better, that's not in dispute. But because it compiles early, it can't do some things that runtime compilers do, and do well. That's all I'm saying here. No need to get all defensive!
Tobias notes that I should use -flto, and Eki asks why I have forbidden GCC to inline. Brennan also suggests that I have allowed V8 to run optimally. That is not the case. The point for me was to foil static inlining attempts in both. (See, I come from the Scheme world, where people know how to inline lexically, but generally don't know V8's dynamic inlining trick.) So in V8 I also compiled f and g in separate compilation units. -flto is just another opportunity to statically inline. Anyway GCC did not decide to do it at -O2, the flags that I used, and can't do it for a tight loop calling into a shared library.
Oddly enough there was the criticism that this isn't real enough code. Of course it's a silly thing, and of course GCC is better for most real code. I didn't intend to benchmark it when I started looking into it for my previous article, but it was indeed amusing. That said, the fact that most current systems don't really handle tight loops across compilation units affects the way that people write real systems, providing an artificial constraint to program construction.
Finally... the tone has really gotten terrible here. Please think before you write. Thanks!
The title is very much a button-pusher. I assumed it was it was meant to be tongue-in-cheek, but if you're serious then I'm afraid even I feel you've may have made a quantum leap to the conclusion. It seems like v8 does some really clever things, and I agree with almost everything you've mentioned, except the title itself.
On the flip side, I am weary of C/C++ apologists that get worked up at the suggestion that other languages have their merits. It poisons discourse. To those people all I can say is, "calm down." C and C++ will be with us for a long time to come, even if advances in compiler technology are making languages like javascript "fast enough" for an increasing variety of purposes.
Oh, man, have a sense of humor. I love this post. It just showed that in some cases, JIT may be faster than a static compiler like GCC. What's wrong with this opinion? The data explained all. The author never said "let's forget C/C++ and use JS from now on."
If I'm not mistaken, there were several points (2^24 through 2^30) where V8 was faster than the gcc-compiled code, even excluding compilation time. If you assume an already running V8, there are a few more.
Would the compiled runtimes catch up if they were compiled using profile-guided optimization? (Obviously, that makes the comparison even more favorable to V8 in the run-only-a-few-times case.)
Similar things have been done with other jits before.
http://morepypy.blogspot.com/2011/02/pypy-faster-than-c-on-carefully-crafted.html
http://morepypy.blogspot.com/2011/08/pypy-is-faster-than-c-again-string.html
I would like to point out that your choice of data to graph, and the axes you chose to graph it on, is extremely hard to read. The data does support your statement (I was relieved to see, since hard-to-read graphs are usually a sign of funny business) but at first glance it looks like it *refutes* the statement.
Why did you choose to graph *total* v8 time and gcc *compile* time together? Why not totals for both? Or at least, run and compile times for both, preferably stacked on top of each other. You can still keep the relative % scale, it's just confusing to use two different metrics for data that shows up side-by-side.
Also at first glance it's easy to miss that the X axis is logarithmic. It'd be better to use an axis with logarithmic tick marks and true value labels, or at the very least label with 2^N directly instead of hiding that detail in the label.
Because of both of these, I seriously stared at this and thought "wow, GCC is faster at only 24 iterations" for a few minutes.
Just found this graphpost, and wonder if you’re serious.
Did you want to see whether GCC compilation would be a better fit for optimizing JS on the web?