git and bzr
A DVCS survey went out recently to GNOME SVN committers, and the results came out a couple days ago. There is much nuance to pull out of the data, but I think that it's fair to say that the respondents prefer git.
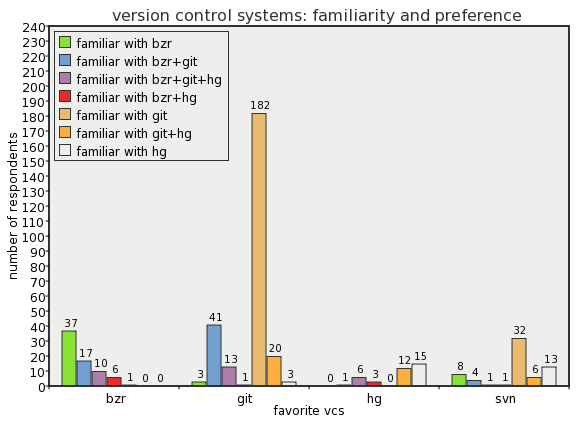
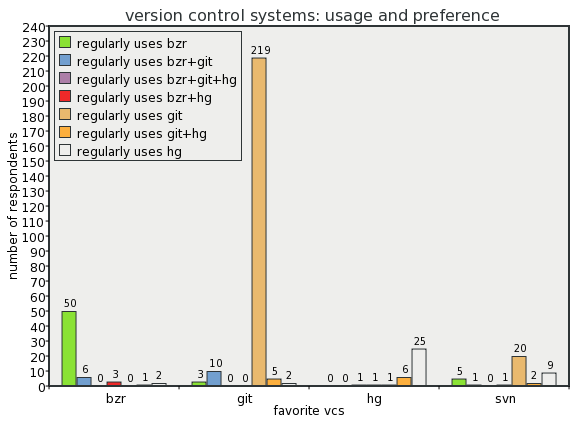
(Script here, requires latest guile-charting from bzr.)
The survey was not posited as a referendum on whether or not GNOME should switch to a particular DVCS, but it certainly sheds light on the question.
Unfortunately, the resulting thread on desktop-devel has been quite nasty -- there are a lot of very legitimate concerns coming out, but even Behdad (whom I respect) at one point took an entirely reasonable post as a personal attack.
This is looney.
We're not here to win some kind of victory over each other, to turn other people into losers -- we're here to build something that's bigger than we are. We should remember this when we communicate. We should read at a deeper level to find out what's really on people's minds, to acknowledge those concerns, and work from there to build things, not to tear people down.
Enough of that. One of the options on the table was a really neat hack from John Carr, in which repositories could be accessed via git or bzr.
So, everyone should see this as being a pretty sweet hack, I think. But it has many downsides, and not all of them were mentioned in the ensuing discussion:
The canonical repository format would be bzr, not git. Preferences for git often are based on its semantic model and repository format, so this would be going against developer preference.
Thus, bzr web tools would probably be used instead of git web tools. Personally I prefer cgit and gitweb to loggerhead, though loggerhead has improved quite a bit recently.
Bzr revisions would be the primary way to refer to code. You couldn't say "check revision 034fea225", you'd have to say "check revision 1". So in practice, bzr and git would not be equal, neither from the admin side, nor the developer side.
I was one of the 14 respondents of the survey that actually *use* bzr and git. I mantain many projects in bzr, but am in the slow process of switching to git. Initially I was attracted by the bzr idea that you can usefully refer to revisions by simple numbers, but time has convinced me otherwise.
I want my family jewels in a safe place. When I refer to a revision, I mean that revision and not another tree and history that happens to be the 35th in a series of patches.
Joe Shaw has a few more.
There is of course the important caveat regarding renaming, which many git proponents fail to acknowledge. But my instincts are that if git works for the kernel, its renaming heuristic failure rate should be equivalent to the rate of me starting a new file, but saying it was a copy, or my starting a copy and saying it came ex nihilo. But that's just my feeling -- I have no data on that.
apologies from a git supporter
As one who now prefers git, I would like to apologize to users of other version control systems, especially bzr: for the VCS BOF at GUADEC that wasn't, for the tone of git proponents, for the FUD, and for a general lack of respect. And for ongoing git UI crappiness, though it has improved quite a bit.
But I think that git's the best thing going, and so do most of the other survey respondents. We should figure out a pragmatic way forward that takes all perspectives into account, and I think that Behdad's proposal is a good start.
12 responses
Comments are closed.
Are you aware that Bazaar also has Git-style globally unique identifiers for each revision? They are not displayed by default, try using `bzr log --show-ids`. The "revision 1" style is merely the default presentation in the user interface.
My opinion doesn't matter, anyway I hope that gnome will adopt only a single DVCS (and not every DVCS out there, or a strange combination of them) and build a github like community (gnomehub?) around it (you can already do that with git+gitorious for example), that alone will really help to expand and revitalize the gnome community in new directions; I can't stop thinking what a github like model can bring to the gnome ecosystem, just think about translations [1]...
PS
I've used bzr, hg and git, I think hg and git are pretty much at the same level (git has got a nicer branching model and more momentum) and both represent the best of the DVCS world as of now, they are based on a pretty simple underlying model and despite what most people say I think the have a nicer, simpler and basic UI than bzr
[1] http://github.com/blog/255-git-ist-schnell
@John: I am, but there are a couple of problems with them AFAIK:
(1) they're not promoted as being the *primary* way to refer to revisions
(2) they don't hash their contents, they're just random identifiers. (I could be wrong on this point.) Content-based addressing makes me feel warm and fuzzy.
@michele: GNOME + gitorious would be fantastic, I agree!
I only have one concern in all these discussions. Git may be just fine for super-power-extra-mega-users, which is easily shown when all these users talk about is how they can rewrite the history of old branches and other esoteric stuff like that. But it is fucking unfriendly if you aren't a supersupermegahacker. If that's the only people that should be allowed to hack on GNOME, then go Git.
@Stoffe: You're right that git excites some people for its "ooh I have a power tool" nature.
But, and your experience might be different, I think you'll find that today's Git is much easier to use than it used to be. For the beginner, or someone familiar with another VCS, it's still not as good as bzr of course, but it's getting there.
@Stoffe as Andy said nowadays git ui is much improved and all the fancy feature power users like are confined to external commands, I don't want to sound repetitive but the github uptake is another sign of how much git has become usable by normal people and not only by super-power-extra-mega-users. ;-)
Ad again, an opensource tool like gitorious represents a viable solution to easily reproduce a github like experience
For having used both gitorious and github I can say github rocks more, even though it's not open-source. I find github superior to gitorious on the social level and the UI is much more attractive ;) But i think the discussion is derivating a bit ;)
An OSS github clone would be indeed nice, maybe improving gitorious is the way to go, but much work ahead.
Nice post Andy!
One of the downsides of using content hashes to identify revisions is performing repeatable partial imports from another revision control system.
Without importing the full history, it isn't possible to know the names of any of the revisions you are interested in. In contrast, if revision names are arbitrary strings you can define a mapping of the foreign VCS revision IDs into the new system's revision ID domain.
One tool I've used that depended on this was the Arch -> Bazaar importer, which could import branches one Arch archive at a time (which would often leave you with missing revisions for merges). Being able to perform an import of additional archives as I found them and integrate them into my original import was pretty useful.
Another example would be integrating the old history of the Linux kernel into the current git repo. As they started without a full import of the BitKeeper history, it wasn't possible to keep the git revision IDs consistent with what they would have been had they started with that history. I know you can use git grafts here, but that seems to be a hack around the problem of using a content hash as a revision identifier.
I do agree that you want to have some assurance that a revision really is the one it claims to be though. But I think a digital signature is a better option than a content hash.
@Stoffe
I've only recently started using git, so I can't comment on what it used to be like. But I've found it pretty easy to get the hang of, and I'd certainly not describe myself as any kind of expert tool hacker. Perhaps you should take another look at it, if you've not done so for a while?
There really should be no caveats with regard to git renaming, given that git renaming is all inferred after-the-fact. Nothing regarding renaming/copying is stored in the repository itself, so if it displays incorrectly that something was renamed/copied, you can just turn off inferring of this info, or even contribute patches back to git.git to improve rename detection. Since nothing is stored in the repo regarding this, any improvements made to git.git will apply to all your old repos.
Hey Andy. I'm definitely in agreement with you about unique id's as the way of addressing commits, but I'm not so warm and fuzzy about content addressability as I was.
The main issue I have now is that *in git* the hash is assumed to be unbreakable - i.e. if you sign a tag or commit, you're only signing the sha1 of the commit. That's usually a fail assumption ;)
A fix for this would be if a tag stored an arbitrary hash of all the commits and subobjects, but we're getting a bit messy then.
The other things that I like about using a uuid rather than a content hash are a bit more pragmatic, it allows you to do things like attach revision properties and generally associate more things with an object than just the content. Of course, the downside is that there's more data to lose, though in both a git pack and a bzr pack, if you lose a choice small part you can end up loosing whole swathes of your repo.
@Rob Taylor:
The SHA1's always propagate upwards in git, so when you sign something you're signing a tag that does take into account the entire content of the tree and the history leading up to that tree.
It works like this:
A file is named by the SHA1 hash of its contents.
A tree (collection of files) is "named" by the SHA1 hash of the alpha-sorted on-disk filenames and the SHA1 hashes of the contents of those files (the git filenames, so to speak).
A commit (or revision) is named by its commit-object. The commit-object contains the tree SHA1 and the parent SHA1 hash (or hashes in the case of a merge).
So when you sign a tag pointing to a specific commit, you're signing the content as well as the history leading to that content, and all the log-messages that are part of that history too. It's really quite ingenious.