reducing the footprint of python applications
Last week I was making up notes for today's forthcoming Flumotion 0.5.1 release, which is exciting stuff. We have reduced Flumotion's memory footprint considerably. However, while attempting to quantify this, I noted that the writable memory usage of our manager process actually increased. Unacceptable!
what is my memory footprint?
Optimization must start with accurate benchmarks, to know how much you are improving things (or not), and to know when you can stop. The best commonly-deployed measurement available on Linux systems is the /proc/*/smaps data.
When developing an application that integrates with the rest of your system, the important statistic to get is the amount of writable memory. Writable memory is necessarily local to your process, representing an amount of data that "occupies space" on your system.
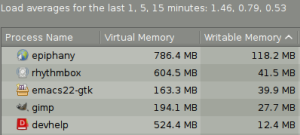
Fortunately, this information is available in Gnome's sytem monitor, System > Administration > System Monitor on my machine. If you don't see a "Writable memory" column, edit your preferences to include it. You can also get the raw smaps information if you right-click on the process in question.
Alternately, from the command line, Maurer's smem.pl script can also summarize the smaps info into a human-readable format, but it requires an external perl module. I found it easier and more entertaining to write my own smaps parser, mem_usage.py, which may be invoked as mem_usage.py PID, assuming that you have the privileges to read that process' smaps file. For example:
wingo@videoscale:~/f/flumotion$ mem_usage.py 9618
Mapped memory:
Shared Private
Clean Dirty Clean Dirty
r-xp 3396 0 500 0 -- Code
rw-p 36 0 8 656 -- Data
r--p 16 0 0 12 -- Read-only data
---p 0 0 0 0
r--s 12 0 0 0
total 3460 0 508 668
Anonymous memory:
Shared Private
Clean Dirty Clean Dirty
r-xp 0 0 0 0
rw-p 0 0 0 19020 -- Data (malloc, mmap)
total 0 0 0 19020
----------------------------------------
total 3460 0 508 19688
In this example (run on flumotion-manager from 0.4.2), we see that the process occupies 19.6 MiB of writable memory, the number in the bottom right of the output.
$ FLU_DEBUG=4 /usr/bin/time \ bin/flumotion-manager conf/managers/default/planet.xml 0.84user 0.21system 0:02.22elapsed 47%CPU (0avgtext+0avgdata 0maxresident)k 0inputs+0outputs (0major+6472minor)pagefaults 0swaps
Another useful, widely deployed tool is GNU's time, which is different from the bash builtin. The number of page faults, while not a stable number, can give a general idea of your application's VM footprint. See section 7.1 of Drepper's memory paper for more information on these numbers.
plugging memory leaks
Once your footprint is known, you can start to take a look at what is actually using memory. With Python this presents a challenge in that most tools are designed to debug C and not Python programs -- they analyze the C stack, the libc allocator, etc. We have a few options at our disposal, though.
PySizer works well for me in answering the question, "what objects are allocated in Python, and how much memory do they take". PySizer provides low-level tools for fondling python's heap, with a pretty good tutorial, check it out. Version 0.1.1 has worked for me. I have found that with my unpatched Python 2.5 that the simplegroupby results are not entirely accurate, however.
To me, PySizer is more useful when investigating memory leaks than when doing static memory profiles. In addition to being able to annotate objects with their referents and referrers, you can take a diff beteen two scan operations, allowing you to see where objects were actually leaked.
Another option to consider is Heapy, which looks better than PySizer, but it segfaults for me. Probably an x86-64-related problem.
People writing applications with Twisted might be interested in Flumotion's AllocMonitor, which bundles up this functionality into a poller that periodically prints out newly allocated objects. Running a full scan of the heap is relatively expensive, so it's not something you'd want to run in production, but it has proved useful to me.
One nice leak that I found a while back was a reference cycle involving an object with a __del__ method. Turns out, Python's garbage collector doesn't free these at all (search for __del__ on the docs for the gc module). Trouble is, it doesn't warn you about this either, leading to a silent leak. The UncollectableMonitor polls gc.garbage every couple minutes, printing out some nasty warnings if it finds uncollectable garbage. Nasty, but worth running in production.
So what happens when your boss tells you that some critical process has 455 MB of resident memory, and asks you to figure out what's going on? Obviously taking up that much memory is not without its performance problems. The question is the same, though: what's taking up all that memory? How long is that list, anyway?
In this case I've found it invaluable to be able to get a Python prompt on a running, daemonized process via Twisted's horrendously underdocumented manhole code. You might find the wrapper I wrote to be easier to use. The flumotion manhole module exports functions to open a manhole either over ssh (authenticating against some authorized keys file, e.g. ~/.ssh/authorized_keys) or over telnet (no authentication), to which you can ssh or telnet to from a terminal.
Manhole is pretty neat. It offers an interactive command-prompt that integrates with the reactor, so that your daemon keeps on doing its thing while you're typing in expressions. Its support for line editing is rudimentary, but it works pretty well, and has helped me to plug a number of leaks in Flumotion, allowing me to poke around in the program's state and run the AllocMonitor if needed.
what's taking all that memory?
Tackling the steady-state memory footprint of a python daemon is more of a black art. I have no general techniques here. However, I would like to mention how we reduced memory use in a number of cases.
One big improvement that we made was to remove unnecessary libraries from long-running processes. You can see what libraries are loaded into an application via looking at gnome-system-monitor's smaps information, and sorting in descending order of private dirty memory. Each library loaded takes at least a page of memory for the jump tables, and in some cases quite a bit more for library-private data. For example, Maurer notes, "[a]n extreme example of this is libaudiofile. This library has 92 kb of dirty, private rss (isn't that naughty!)."
Odd to find, then, that our Gtk+ administration program loads libaudiofile, when we didn't even use it! It turns out that this came from a line in our Glade XML files, <requires lib="gnome"/>. This little line caused libglade to load up libgnomeui, which then pulls in lots of unnecessary things. I removed those lines with no effect at all, we weren't even using the deprecated libgnomeui widgets.
Another big win is a bit painful to mention, as an erstwhile GStreamer hacker. Loading GStreamer takes up quite a bit of memory. The amount of writable memory that it takes up appears to depend on the size of your registry, and of course the whether you have a 32-bit or a 64-bit userspace. On one of our 32-bit production servers, "import gst" causes a simple python listener's writable memory usage to increase by 1.3MB. On my 64-bit desktop with more plugins installed, more than 5 MB extra is consumed!
There are two ways to look at this problem. One of them is to make a binary, mmap(2)able registry, which will put the information from the registry into a read-only memory segment. The other obvious solution is to remove GStreamer from processes that don't need it, which in Flumotion is every process that does not directly process sound or video data. In one process, we even introduced a fork so that the a short-running function that needs GStreamer would not impact the memory footprint of the long-running process.
Note that not all libraries are as heavy as this, though. For example, "import gobject" only causes a 200 kB increase on my 64-bit system. In fact, in an effort to remove gobject from some processes, I think that I actually increased writable memory usage, via forcing the use of python's optparse and not gobject's GOption code.
Not coincidentally, Flumotion has a registry as well, modeled after GStreamer's. It suffers from the same problems, but more acutely. I knew this intuitively, and so removed registry parsing from all processes but the manager, but it wasn't until I ran Valgrind's Massif on the manager that I knew the extent of the problem.
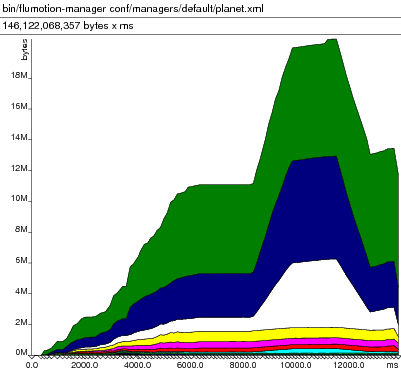
The above image shows memory allocation within flumotion's manager process over time, at startup. The problem with Massif and Python, of course, is that it shows you an inappropriate level of detail. It would be nice to be able to annotate the interaction between the program and Massif so that you could, for example, show on the graph when individual modules are loaded.
Barring that, I started up the manager under strace, along with verbose Flumotion logging and python logging, which shows me when modules are loaded.
The first thing that I saw was lots of open() calls and read() calls on all of the source files in the flumotion tree, which turned out to be an embarrassing bug in which we were actually computing an md5sum for all flumotion source files at startup. Yikes! While not really a memory problem, that was killing our startup performance. Fixed that, and a couple of other filesystem use inefficiencies.
Then next thing that I saw was our real problem:
open("/home/wingo/f/flumotion/cache/registry/registry.xml", O_RDONLY) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=116402, ...}) = 0
fstat(3, {st_mode=S_IFREG|0644, st_size=116402, ...}) = 0
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x2ae8fac27000
read(3, "\n\n \n\n "..., 16384) = 16384
brk(0x1137000) = 0x1137000
brk(0x118b000) = 0x118b000
brk(0x11ac000) = 0x11ac000
brk(0x11cd000) = 0x11cd000
brk(0x11ee000) = 0x11ee000
...
brk(0x1a2e000) = 0x1a2e000
brk(0x1a86000) = 0x1a86000
brk(0x1ac6000) = 0x1ac6000
It was reading and parsing our registry file that was causing that enormous memory spike in the image. (brk is a low-level system call that allocates more heap for a process, and is often used in malloc implementations.) Simple subtraction from the last segment position to the first yields almost 10 MB allocated while reading a 116 kB XML file. Ouch!
What's worse, that memory was never given back to the system, despite the recent work on the python memory allocator -- there were no subsequent munmap(2) calls, and the segment was never moved back. So that usage spike that valgrind showed us had longer-lasting effects: writable memory usage of that process never dropped below its maximum. Presumably this was because the heap was left in an extremely fragmented state, with the live objects spread over many pages, so that no page could be returned to the OS.
As is the case with GStreamer, Flumotion's registry is just a cache, though; logically a union of the information available in many small files spread through the Flumotion tree. It is recalculated as necessary. As a temporary solution to this problem, I made Flumotion not look for this cache, instead traversing the tree and reconstructing the registry via the parsing of these many small files. This leads to a sawtooth memory use pattern, rather than the "big spike" from above, leaving the heap more compact and less fragmented. This strategy has real effects, saving 7 or 8 MB of writable memory on my machine.
The downside of course is that with a cold cache, you cause many disk seeks as the directories are traversed and all of the file snippets are read. The real solution would be to make some kind of registry cache format that does not impose an 80-times memory penalty as XML DOM parsing does. However, in our case with 100+ managers running on one server, the memory benefits are key, and the registry snippets will likely be loaded from disk cache anyway.
Note that in trunk Valgrind, Massif has been completely rewritten, and doesn't appear to do graphs yet. I used the 3.2.3 version that is packaged on my Debian-derived distro, which worked well. The massif graph was interesting for one thing: it shows that 5 MB are allocated via CRYPTO_malloc, so I tried running Flumotion without SSL. Indeed, writable memory usage is 5 MB lower. Probably more low-hanging fruit there.
lessons
pysizer is useful for detecting what objects are being leaked
avoid __del__ and reference cycles, and monitor gc.garbage
strace tells you what crack things you're doing
massif interesting, but misleading as to your total footprint
writable memory numbers are the most important
CPython's memory footprint is terrible; not only is all code stored in private dirty memory, all code and data that is used is written to when twiddling refcounts
64-bit python processes use about twice the memory as 32-bit
reducing number of linked libraries often helps, but not always
Finally, I'd like to show the output of mem_usage.py on flumotion-manager from trunk:
wingo@videoscale:~/f/flumotion$ mem_usage.py 10784
Mapped memory:
Shared Private
Clean Dirty Clean Dirty
r-xp 2748 0 508 0 -- Code
rw-p 36 0 8 608 -- Data
r--p 16 0 0 12 -- Read-only data
---p 0 0 0 0
r--s 12 0 0 0
total 2812 0 516 620
Anonymous memory:
Shared Private
Clean Dirty Clean Dirty
r-xp 0 0 0 0
rw-p 0 0 0 12800 -- Data (malloc, mmap)
total 0 0 0 12800
----------------------------------------
total 2812 0 516 13420
$ FLU_DEBUG=4 /usr/bin/time \ bin/flumotion-manager conf/managers/default/planet.xml 0.80user 0.04system 0:01.84elapsed 45%CPU (0avgtext+0avgdata 0maxresident)k 0inputs+0outputs (0major+4596minor)pagefaults 0swaps
Dropped 6 MiB and 2000 page faults from the manager, not bad at all!
16 responses
Comments are closed.
The 'gtop' gnome-python-desktop modules provides what you want. gtop.proc_map
Anyway, hundred of megabytes of mapping
Anyway, hundred of megabytes of mapping is still worying
Benoît: Thanks for the tip, the gtop module sounds quite useful! The output of my script is in kilobytes, btw; still too much, but there's only about 24 megabytes of memory that's mapped.
I was actually wondering about rhythmbox and epiphany :D
Wow, that was a fantastic post.
Most developers [should] go through the mem reduction process,
but very few document it, and much fewer again with this quality.
I've a popular python script for summarising mem used
by all running programs which I try to keep up to date
with the latest kernel instrumentation data available:
http://www.pixelbeat.org/scripts/ps_mem.py
Pádraig: Thanks! I actually did use your script, but I wanted to run it on some of our production machines and did not want to run it as root. You might consider making it just profile the processes for which you have permissions if euid != 0.
I also wanted to experiment with some of the data that David Schleef analyzes in his mem_usage script: http://www.schleef.org/~ds/mem_usage. It's interesting to break down the maps by permissions, but ultimately less useful than the "shared/private" and "clean/dirty" distinction, IMO.
Python does have a way to warn about __del__ methods that keep garbarge around. See the gc module docs (specifically, DEBUG_UNCOLLECTABLE).
Neil: Good point, I had forgotten about that. Probably better than my hacky polling solution.
It looks like you're using xml.dom.minidom for your XML parsing. That does have a large overhead; you'd probably be much happier (memory-wise) with ElementTree. See David Mertz's developerWorks article http://www.ibm.com/developerworks/xml/library/x-matters28/ .
Very, very interesting.
Can you explain a little what you mean by writable memory in shared libraries?
If you have a 1MB library and 10 apps link to it, doesn't it only take 1MB of physical memory? But you're saying that depending on the library, each linked application may have it's own section (lets say 100k) that is just theirs (and not shared)? Thus 10 apps linking to this app take 11MB physical memory?
Am I correct in understanding?
[...] reducing the footprint of python applications — andy wingo (tags: toread) [...]
[...] http://wingolog.org/archives/2007/11/27/reducing-the-footprint-of-python-applications [...]
Re: Heappy, it's known it won't work with 64bit; for 32bit folk, a doc that might be useful is available at http://www.pkgcore.org/trac/pkgcore/doc/dev-notes/heapy.rst
[...] Анализ во время выполнения с помощью с помощью довольно замысловатых утилит из этого поста ни к чему не привёл - нет ничего. Я пробовал считать количество объектов, которые видит модуль gc в питоне (то есть тех, кто поддерживает garbage collection), но количество не растет существенно и пропорционально нагрузке на сервер. Однако память процесс кушает и довольно быстро. [...]
Thanks for this. It is really helpful. I am currently working on a Python function benchmark. I would like to track the memory footprint of the function with this. I already looked at PySizer and Heapy but those feel a bit heavy. What would you recommend?
I am trying to optimize django manage.py commands.
It is taking too much memory how do I start?