My readers will know that I have recently had the pleasure of looking into the V8 JavaScript implementation, from Google. I'm part of a small group in Igalia doing compiler work, and it's clear that in addition to being lots of fun, JavaScript implementations are an important part of the compiler market today.
But V8 is not the only JS implementation in town. Besides Mozilla's SpiderMonkey, which you probably know, there is another major Free Software JS implementation that you might not have even heard of, at least not by its proper name: JavaScriptCore.
jsc: js for webkit
JavaScriptCore (JSC) is the JavaScript implementation of the WebKit project.
In the beginning, JavaScriptCore was a simple tree-based interpreter, as Mozilla's SpiderMonkey was. But then in June of 2008, a few intrepid hackers at Apple wrote a compiler and bytecode interpreter for JSC, threw away the tree-based interpreter, and called the thing SquirrelFish. This was eventually marketed as "Nitro" inside Apple's products[0].
JSC's bytecode interpreter was great, and is still pretty interesting. I'll go into some more details later in this article, because its structure conditions the rest of the implementation.
But let me continue here with this historical sketch by noting that later in 2008, the WebKit folks added inline caches, a regular expression JIT, and a simple method JIT, and then called the thing SquirrelFish Extreme. Marketers called this Nitro Extreme. (Still, the proper name of the engine is JavaScriptCore; Wikipedia currently gets this one wrong.)
One thing to note here is that the JSC folks were doing great, well-factored work. It was so good that SpiderMonkey hackers at Mozilla adopted JSC's regexp JIT compiler and their native-code assembler directly.
As far as I can tell, for JSC, 2009 and 2010 were spent in "consolidation". By that I mean that JSC had a JIT and a bytecode interpreter, and they wanted to maintain them both, and so there was a lot of refactoring and tweaking to make them interoperate. This phase consolidated the SFX gains on x86 architectures, while also adding implementations for ARM and other architectures.
But with the release of V8's Crankshaft in late 2010, the JS performance bar had been lowered again (assuming it is a limbo), and so JSC folks started working on what they call their "DFG JIT" (DFG for "data-flow graph"), which aims be more like Crankshaft, basically.
It's possible to configure a JSC with all three engines: the interpreter, the simple method JIT, and the DFG JIT. In that case there is tiered compilation between the three forms: initial parsing and compilation produces bytecode, that can be optimized with the method JIT, that can be optimized by the DFG JIT. In practice, though, on most platforms the interpreter is not included, so that all code runs through the method JIT. As far as I can tell, the DFG JIT is shipping in Mac OS X Lion's Safari browser, but it is not currently enabled on any platform other than 64-bit Mac. (I am working on getting that fixed.)
a register vm
The interpreter has a number of interesting pieces, but it is important mostly for defining the format of bytecode. Bytecode is effectively the high-level intermediate representation (IR) of JSC.
To put that into perspective, in V8, the high-level intermediate representation is the JS source code itself. When V8 first sees a piece of code, it pre-parses it to raise early syntax errors. Later when it needs to analyze the source code, either for the full-codegen compiler or for Hydrogen, it re-parses it to an AST, and then works on the AST.
In contrast, in JSC, when code is first seen, it is fully parsed to an AST and then that AST is compiled to bytecode. After producing the bytecode, the source text isn't needed any more, and so it is forgotten. The interpreter interprets the bytecode directly. The simple method JIT compiles the bytecode directly. The DFG JIT has to re-parse the bytecode into an SSA-style IR before optimizing and producing native code, which is a bit more expensive but worth it for hot code.
As you can see, bytecode is the common language spoken by all of JSC's engines, so it's important to understand it.
Before really getting into things, I should make an aside about terminology here. Traditionally, at least in my limited experience, a virtual machine was considered to be a piece of software that interprets sequences of virtual instructions. This would be in contrast to a "real" machine, that interprets sequences of "machine" or "native" instructions in hardware.
But these days things are more complicated. A common statement a few years ago would be, "is JavaScript interpreted or compiled?" This question is nonsensical, because "interpreted" or "compiled" are properties of implementations, not languages. Furthermore the implementation can compile to bytecode, but then interpret that bytecode, as JSC used to do.
And in the end, if you compile all the bytecode that you see, where is the "virtual machine"? V8 hackers still call themselves "virtual machine engineers", even as there is no interpreter in the V8 sources (not counting the ARM simulator; and what of a program run under qemu?).
All in all though, it is still fair to say that JavaScriptCore's high-level intermediate language is a sequence of virtual instructions for an abstract register machine, of which the interpreter and the simple method JIT are implementations.
When I say "register machine", I mean that in contrast to a "stack machine". The difference is that in a register machine, all temporary values have names, and are stored in slots in the stack frame, whereas in a stack machine, temporary results are typically pushed on the stack, and most instructions take their operands by popping values off the stack.
(Incidentally, V8's full-codegen compiler operates on the AST in a stack-machine-like way. Accurately modelling the state of the stack when switching from full-codegen to Crankshaft has been a source of many bugs in V8.)
Let me say that for an interpreter, I am totally convinced that register machines are the way to go. I say this as a Guile co-maintainer, which has a stack VM. Here are some reasons.
First, stack machines penalize named temporaries. For example, consider the following code:
(lambda (x)
(* (+ x 2)
(+ x 2)))
We could do common-subexpression elimination to optimize this:
(lambda (x)
(let ((y (+ x 2)))
(* y y)))
But in a stack machine is this really a win? Consider the sequence of instructions in the first case:
; stack machine, unoptimized
0: local-ref 0 ; x
1: make-int8 2
2: add
3: local-ref 0 ; x
4: make-int8 2
5: add
6: mul
7: return
Contrast this to the instructions for the second case:
; stack machine, optimized
0: local-ref 0 ; push x
1: make-int8 2 ; push 2
2: add ; pop x and 2, add, and push sum
3: local-set 1 ; pop and set y
4: local-ref 1 ; push y
5: local-ref 1 ; push y
6: mul ; pop y and y, multiply, and push product
7: return ; pop and return
In this case we really didn't gain anything, because the storing values to locals and loading them back to the stack take up separate instructions, and in general the time spent in a procedure is linear in the number of instructions executed in the procedure.
In a register machine, on the other hand, things are easier, and CSE is definitely a win:
0: add 1 0 0 ; add x to x and store in y
1: mul 2 1 1 ; multiply y and y and store in z
2: return 2 ; return z
In a register machine, there is no penalty to naming a value. Using a register machine reduces the push/pop noise around the instructions that do the real work.
Also, because they include the names (or rather, locations) of their operands within the instruction, register machines also take fewer instructions to do the job. This reduces dispatch cost.
In addition, with a register VM, you know the size of a call frame before going into it, so you can avoid overflow checks when pushing values in the function. (Some stack machines also have this property, like the JVM.)
But the big advantage of targeting a register machine is that you can take advantage of traditional compiler optimizations like CSE and register allocation. In this particular example, we have used three virtual registers, but in reality we only need one. The resulting code is also closer to what real machines expect, and so is easier to JIT.
On the down side, instructions for a register machine typically occupy more memory than instructions for a stack machine. This is particularly the case for JSC, in which the opcode and each of the operands takes up an entire machine word. This was done to implement "direct threading", in which the opcodes are not indexes into jump tables, but actually are the addresses of the corresponding labels. This might be an acceptable strategy for an implementation of JS that doesn't serialize bytecode out to disk, but for anything else the relocations are likely to make it a lose. In fact I'm not sure that it's a win for JSC even, and perhaps the bloat was enough of a lose that the interpreter was turned off by default.
Stack frames for the interpreter consist of a six-word frame, the arguments to the procedure, and then the locals. Calling a procedure reserves space for a stack frame and then pushes the arguments on the stack -- or rather, sets them to the last n + 6 registers in the stack frame -- then slides up the frame pointer. For some reason in JSC the stack is called the "register file", and the frame pointer is the "register window". Go figure; I suppose the names are as inscrutable as the "activation records" of the stack world.
jit: a jit, a method jit
I mention all these details about the interpreter and the stack (I mean, the register file), because they apply directly to the method JIT. The simple method JIT (which has no name) does the exact same things that the bytecode interpreter does, but it does them via emitted machine instructions instead of interpreting virtual instructions.
There's not much to say here; jitting the code has the result you would expect, reducing dispatching overhead, while at the same time allowing some context-specific compilation, like when you add a constant integer to a variable. This JIT is really quick-and-dirty though, so you don't get a lot of the visibility benefits traditionally associated with method JITs like what HotSpot's C1 or C2 currently have. Granted, the register VM bytecode does allow for some important optimizations to happen, but JSC currently doesn't do very much in the way of optimizing bytecode, as far as I can tell.
Thinking more on the subject, I suspect that for Javascript, CSE isn't even possible unless you know the types, as a valueOf() callback could have side effects.
an interlude of snarky footnotes
Hello, reader! This is a long article, and it's a bit dense. I had some snarky footnotes that I enjoyed writing, but it felt wrong to put them at the end, so I thought it better to liven things up in the middle here. The article continues in the next section.
0. In case you didn't know, compilers are approximately 37% composed of marketing, and rebranding is one of the few things you can do to a compiler, marketing-wise, hence the name train: SquirrelFish, Nitro, SFX, Nitro Extreme...[1] As in, in response to "I heard that Nitro is slow.", one hears, "Oh, man they totally fixed that in SquirrelFish Extreme. It's blazingly fast![2]"
1. I don't mean to pick on JSC folks here. V8 definitely has this too, with their "big reveals". Firefox people continue to do this for some reason (SpiderMonkey, TraceMonkey, JaegerMonkey, IonMonkey). I expect that even they have forgotten the reason at this point. In fact the JSC marketing has lately been more notable in its absence, resulting in a dearth of useful communication. At this point, in response to "Oh, man they totally are doing a great job in JavaScriptCore", you're most likely to hear, "JavaScriptCore? Never heard of it. Kids these days hack the darndest things."
2. This is the other implement in the marketer's toolbox: "blazingly fast". It means, "I know that you don't understand anything I'm saying, but I would like for you to repeat this phrase to your colleagues please." As in, "LLVM does advanced TBAA on the SSA IR, allowing CSE and LICM while propagating copies to enable SIMD loop vectorization. It is blazingly fast."
dfg: a new crankshaft for jsc?
JavaScriptCore's data flow graph (DFG) JIT is work by Gavin Barraclough and Filip Pizlo to enable speculative optimizations for JSC. For example, if you see the following code in JS:
a[i++] = 0.7*x;
then a is probably an array of floating-point numbers, and i is probably an integer. To get great performance, you want to use native array and integer operations, so you speculatively compile a version of your code that makes these assumptions. If the assumptions don't work out, then you bail out and try again with the normal method JIT.
The fact that the interpreter and simple method JIT have a clear semantic model in the form of bytecode execution makes it easy to bail out: you just reconstruct the state of the virtual registers and register window, then jump back into the code. (V8 calls this process "deoptimization"; the DFG calls it "speculation failure".)
You can go the other way as well, switching from the simple JIT to the optimized DFG JIT, using on-stack replacement. The DFG JIT does do OSR. I hear that it's needed if you want to win Kraken, which puts you in lots of tight loops that you need to be able to optimize without relying on being able to switch to optimized code only on function re-entry.
When the DFG JIT is enabled, the interpreter (if present) and the simple method JIT are augmented with profiling information, to record what types flow through the various parts of the code. If a loop is executed a lot (currently more than 1000 times), or a function is called a lot (currently about 70 times), the DFG JIT kicks in. It parses the bytecode of a function into an SSA-like representation, doing inlining and collecting type feedback along the way. This probably sounds very familiar to my readers.
The difference between JSC and Crankshaft here is that Crankshaft parses out type feedback from the inline caches directly, instead of relying on in-code instrumentation. I think Crankshaft's approach is a bit more elegant, but it is prone to lossage when GC blows the caches away, and in any case either way gets the job done.
I mentioned inlining before, but I want to make sure that you noticed it: the DFG JIT does do inlining, and does so at parse-time, like HotSpot does. The type profiling (they call it "value profiling") combined with some cheap static analysis also allows the DFG to unbox int32 and double-precision values.
One thing that the DFG JIT doesn't do, currently, is much in the way of code motion. It does do some dead-code elimination and common-subexpression elimination, and as I mentioned before, you need the DFG's value profiles in order to be able to do this correctly. But it does not do loop-invariant code motion.
Also, the DFG's register allocator is not as good as Crankshaft's, yet. It is hampered in this regard by the JSC assembler that I praised earlier; while indeed a well-factored, robust piece of code, JSC's assembler has a two-address interface instead of a three-address interface. This means that instead of having methods like add(dest, op1, op2), it has methods like add(op1, op2), where the operation implicitly stores its result in its first operand. Though it does correspond to the x86 instruction set, this sort of interface is not great for systems where you have more registers (like on x86-64), and forces the compiler to shuffle registers around a lot.
The counter-based optimization triggers do require some code to run that isn't strictly necessary for the computation of the results, but this strategy does have the nice property that the DFG performance is fairly predictable, and measurable. Crankshaft, on the other hand, being triggered by a statistical profiler, has statistically variable performance.
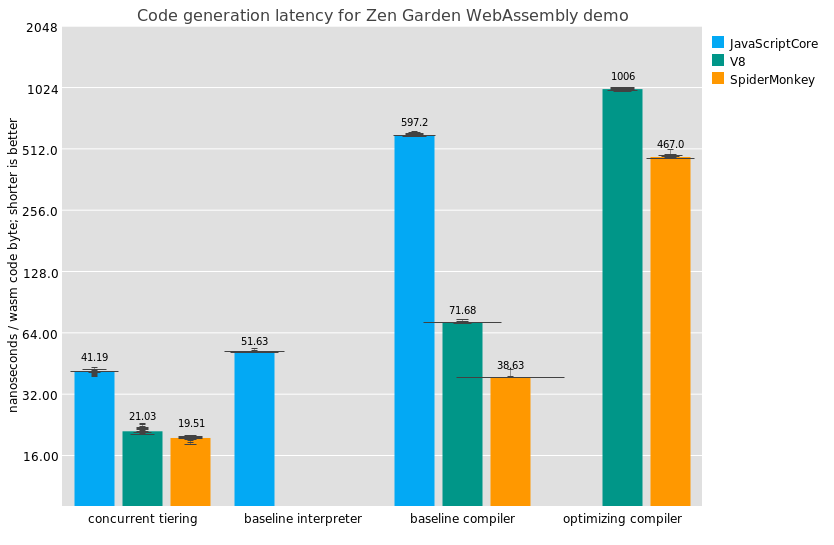
And speaking of performance, AWFY on the mac is really where it's at for JSC right now. Since the DFG is only enabled by default on recent Mac OS 64-bit builds, you need to be sure you're benchmarking the right thing.
Looking at the results, I think we can say that JSC's performance on the V8 benchmark is really good. Also it's interesting to see JSC beat V8 on SunSpider. Of course, there are lots of quibbles to be had as to the validity of the various benchmarks, and it's also clear that V8 is the fastest right now once it has time to warm up. But I think we can say that JSC is doing good work right now, and getting better over time.
future
So that's JavaScriptCore. The team -- three people, really -- is mostly focusing on getting the DFG JIT working well right now, and I suspect they'll be on that for a few months. But we should at least get to the point where the DFG JIT is working and enabled by default on free systems within a week or two.
The one other thing that's in the works for JSC is a new generational garbage collector. This is progressing, but slowly. There are stubs in the code for card-marking write barriers, but currently there is no such GC implementation, as far as I can tell. I suspect that someone has a patch they're cooking in private; we'll see. At least JSC does have a Handle API, unlike SpiderMonkey.
conclusion
So, yes, in summary, JavaScriptCore is a fine JS implementation. Besides being a correct implementation for real-world JS -- something that is already saying quite a lot -- it also has good startup speed, is fairly robust, and is working on getting an optimizing compiler. There's work to do on it, as with all JS implementations, but it's doing fine.
Thanks for reading, if you got this far, though I understand if you skipped some parts in the middle. Comments and corrections are most welcome, from those of you that actually read all the way through, of course :). Happy hacking!