Friends, you might have noted, but over the last year or so I really caught the GC bug. Today’s post sums up that year, in the form of a talk I gave yesterday at FOSDEM. It’s long! If you prefer video, you can have a look instead to the at the FOSDEM event page.
Whippet: A New GC for Guile
4 Feb 2023 – FOSDEM
Andy Wingo
Guile is...
Mostly written in Scheme
Also a 30 year old C library
// API SCM scm_cons (SCM car, SCM cdr); // Many third-party users SCM x = scm_cons (a, b);
So the context for the whole effort is that Guile has this part of its implementation which is in C. It also exposes a lot of that implementation to users as an API.
Putting the C into GC
SCM x = scm_cons (a, b);
Live objects: the roots, plus anything a live object refers to
How to include x into roots?
- Refcounting
- Register (& later unregister) &x with gc
- Conservative roots
So what contraints does this kind of API impose on the garbage collector?
Let’s start by considering the simple cons call above. In a garbage-collected environment, the GC is responsible for reclaiming unused memory. How does the GC know that the result of a scm_cons call is in use?
Generally speaking there are two main strategies for automatic memory management. One is reference counting: you associate a count with an object, incremented once for each referrer; in this case, the stack would hold a reference to x. When removing the reference, you decrement the count, and if it goes to 0 the object is unused and can be freed.
We GC people used to laugh at reference-counting as a memory management solution because it over-approximates the live object set in the presence of cycles, but it would seem that refcounting is coming back. Anyway, this isn’t what Guile does, not right now anyway.
The other strategy we can use is tracing: the garbage collector periodically finds all of the live objects on the system and then recycles the memory for everything else. But how to actually find the first live objects to trace?
One way is to inform the garbage collector of the locations of all roots: references to objects originating from outside the heap. This can be done explicitly, as in V8’s Handle<> API, or implicitly, in the form of a side table generated by the compiler associating code locations with root locations. This is called precise rooting: the GC is aware of all root locations at all code positions where GC might happen. Generally speaking you want the side table approach, in which the compiler writes out root locations to stack maps, because it doesn’t impose any overhead at run-time to register and unregister locations. However for run-time routines implemented in C or C++, you won’t be able to get the C compiler to do this for you, so you need the explicit approach if you want precise roots.
Conservative roots
Treat every word in stack as potential root; over-approximate live object set
1993: Bespoke GC inherited from SCM
2006 (1.8): Added pthreads, bugs
2009 (2.0): Switch to BDW-GC
BDW-GC: Roots also from extern SCM foo;, etc
The other way to find roots is very much not The Right Thing. Call it cheeky, call it sloppy, call it yolo, call it what you like, but in the trade it’s known as conservative root-finding. This strategy looks like this:
uintptr_t *limit = stack_base_for_platform();
uintptr_t *sp = __builtin_frame_address();
for (; sp < limit; sp++) {
void *obj = object_at_address(*sp);
if (obj) add_to_live_objects(obj);
}
You just look at every word on the stack and pretend it’s a pointer. If it happens to point to an object in the heap, we add that object to the live set. Of course this algorithm can find a spicy integer whose value just happens to correspond to an object’s address, even if that object wouldn’t have been counted as live otherwise. This approach doesn’t compute the minimal live set, but rather a conservative over-approximation. Oh well. In practice this doesn’t seem to be a big deal?
Guile has used conservative root-finding since its beginnings, 30 years ago and more. We had our own bespoke mark-sweep GC in the beginning, but it’s now going on 15 years or so that we switched to the third-party Boehm-Demers-Weiser (BDW) collector. It’s been good to us! It’s better than what we had, it’s mostly just worked, and it works correctly with threads.
Conservative roots
+: Ergonomic, eliminates class of bugs (handle registration), no compiler constraints
-: Potential leakage, no compaction / object motion; no bump-pointer allocation, calcifies GC choice
Conservative root-finding does have advantages. It’s quite pleasant to program with, in environments in which the compiler is unable to produce stack maps for you, as it eliminates a set of potential bugs related to explicit handle registration and unregistration. Like stack maps, it also doesn’t impose run-time overhead on the user program. And although the compiler isn’t constrained to emit code to clear roots, it generally does, and sometimes does so more promptly than would be the case with explicit handle deregistration.
But, there are disadvantages too. The potential for leaks is one, though I have to say that in 20 years of using conservative-roots systems, I have not found this to be a problem. It’s a source of anxiety whenever a program has memory consumption issues but I’ve never identified it as being the culprit.
The more serious disadvantage, though, is that conservative edges prevent objects from being moved by the GC. If you know that a location holds a pointer, you can update that location to point to a new location for an object. But if a location only might be a pointer, you can’t do that.
In the end, the ergonomics of conservative collection lead to a kind of calcification in Guile, that we thought that BDW was as good as we could get given the constraints, and that changing to anything else would require precise roots, and thus an API and ABI change, losing users, and so on.
What if I told you
You can find roots conservatively and
- move objects and compact the heap
- do fast bump-pointer allocation
- incrementally migrate to precise roots
BDW is not the local maximum
But it turns out, that’s not true! There is a way to have conservative roots and also use more optimal GC algorithms, and one which preserves the ability to incrementally refactor the system to have more precision if that’s what you want.
Immix
Fundamental GC algorithms
- mark-compact
- mark-sweep
- evacuation
- mark-region
Immix is a mark-region collector
Let’s back up to a high level. Garbage collector implementations are assembled from instances of algorithms, and there are only so many kinds of algorithms out there.
There’s mark-compact, in which the collector traverses the object graph once to find live objects, then once again to slide them down to one end of the space they are in.
There’s mark-sweep, where the collector traverses the graph once to find live objects, then traverses the whole heap, sweeping dead objects into free lists to be used for future allocations.
There’s evacuation, where the collector does a single pass over the object graph, copying the objects outside their space and leaving a forwarding pointer behind.
The BDW collector used by Guile is a mark-sweep collector, and its use of free lists means that allocation isn’t as fast as it could be. We want bump-pointer allocation and all the other algorithms give it to us.
Then in 2008, Stephen Blackburn and Kathryn McKinley put out their Immix paper that identified a new kind of collection algorithm, mark-region. A mark-region collector will mark the object graph and then sweep the whole heap for unmarked regions, which can then be reused for allocating new objects.
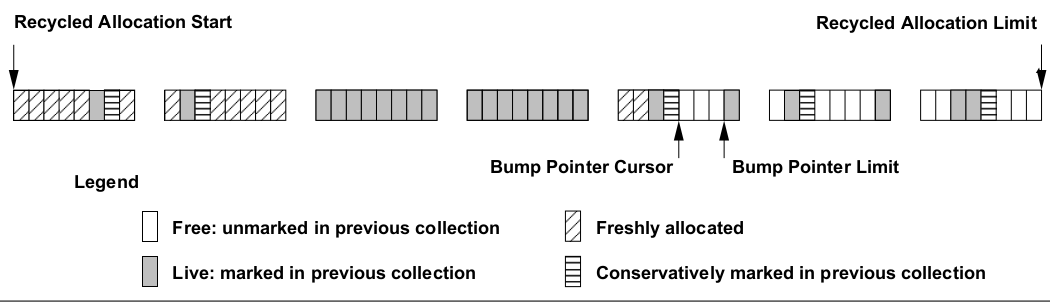
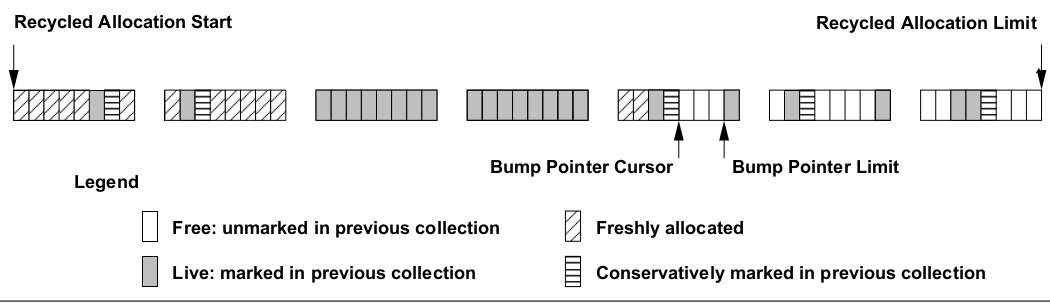
Allocate: Bump-pointer into holes in thread-local block, objects can span lines but not blocks
Trace: Mark objects and lines
Sweep: Coarse eager scan over line mark bytes
Blackburn and McKinley’s paper also describes a new mark-region GC algorithm, Immix, which is interesting because it gives us bump-pointer allocation without requiring that objects be moveable. The diagram above, from the paper, shows the organization of an Immix heap. Allocating threads (mutators) obtain 64-kilobyte blocks from the heap. Blocks contains 128-byte lines. When Immix traces the object graph, it marks both objects and the line the object is on. (Usually blocks are part of 2MB aligned slabs, with line mark bits/bytes are stored in a packed array at the start of the slab. When marking an object, it’s easy to find the associated line mark just with address arithmetic.)
Immix reclaims memory in units of lines. A set of contiguous lines that were not marked in the previous collection form a hole (a region). Allocation proceeds into holes, in the usual bump-pointer fashion, giving us good locality for contemporaneously-allocated objects, unlike freelist allocation. The slow path, if the object doesn’t fit in the hole, is to look for the next hole in the block, or if needed to acquire another block, or to stop for collection if there are no more blocks.
Immix: Opportunistic evacuation
Before trace, determine if compaction needed. If not, mark as usual
If so, select candidate blocks and evacuation target blocks. When tracing in that block, try to evacuate, fall back to mark
The neat thing that Immix adds is a way to compact the heap via opportunistic evacuation. As Immix allocates, it can end up skipping over holes and leaving them unpopulated, and as subsequent cycles of GC occur, it could be that a block ends up with many small holes. If that happens to many blocks it could be time to compact.
To fight fragmentation, Immix decides at the beginning of a GC cycle whether to try to compact or not. If things aren’t fragmented, Immix marks in place; it’s cheaper that way. But if compaction is needed, Immix selects a set of blocks needing evacuation and another set of empty blocks to evacuate into. (Immix has to keep around a couple percent of memory in empty blocks in reserve for this purpose.)
As Immix traverses the object graph, if it finds that an object is in a block that needs evacuation, it will try to evacuate instead of marking. It may or may not succeed, depending on how much space is available to evacuate into. Maybe it will succeed for all objects in that block, and you will be left with an empty block, which might even be given back to the OS.
Immix: Guile
Opportunistic evacuation compatible with conservative roots!
Bump-pointer allocation
Compaction!
1 year ago: start work on WIP GC implementation
Tying this back to Guile, this gives us all of our desiderata: we can evacuate, but we don’t have to, allowing us to cause referents of conservative roots to be marked in place instead of moved; we can bump-pointer allocate; and we are back on the train of modern GC implementations. I could no longer restrain myself: I started hacking on a work-in-progress garbage collector workbench about a year ago, and ended up with something that seems to take us in the right direction.
Whippet vs Immix: Tiny lines
Immix: 128B lines + mark bit in object
Whippet: 16B “lines”; mark byte in side table
More size overhead: 1/16 vs 1/128
Less fragmentation (1 live obj = 2 lines retained)
More alloc overhead? More small holes
What I ended up building wasn’t quite Immix. Guile’s object representation is very thin and doesn’t currently have space for a mark bit, for example, so I would have to have a side table of mark bits. (I could have changed Guile’s object representation but I didn’t want to require it.) I actually chose mark bytes instead of bits because both the Immix line marks and BDW’s own side table of marks were bytes, to allow for parallel markers to race when setting marks.
Then, given that you have a contiguous table of mark bytes, why not remove the idea of lines altogether? Or what amounts to the same thing, why not make line size to be 16 bytes and do away with per-object mark bits? You can then bump-pointer into holes in the mark byte array. The only thing you need to do to that is to be able to cheaply find the end of an object, so you can skip to the next hole while sweeping; you don’t want to have to chase pointers to do that. But consider, you’ve already paid the cost of having a mark byte associated with every possible start of an object, so if your basic object alignment is 16 bytes, that’s a memory overhead of 1/16, or 6.25%; OK. Let’s put that mark byte to work and include an “end” bit, indicating the end of the object. Allocating an object has to store into the mark byte array to initialize this “end” marker, but you need to write the mark byte anyway to allow for conservative roots (“does this address hold an object?”); writing the end at the same time isn’t so bad, perhaps.
The expected outcome would be that relative to 128-byte lines, Whippet ends up with more, smaller holes. Such a block would be a prime target for evacuation, of course, but during allocation this is overhead. Or, it could be a source of memory efficiency; who knows. There is some science yet to do to properly compare this tactic to original Immix, but I don’t think I will get around to it.
While I am here and I remember these things, I need to mention two more details. If you read the Immix paper, it describes “conservative line marking”, which is related to how you find the end of an object; basically Immix always marks the line an object is on and the next one, in case the object spans the line boundary. Only objects larger than a line have to precisely mark the line mark array when they are traced. Whippet doesn’t do this because we have the end bit.
The other detail is the overflow allocator; in the original Immix paper, if you allocate an object that’s smallish but still larger than a line or two, but there’s no hole big enough in the block, Immix keeps around a completely empty block per mutator in which to bump-pointer-allocate these medium-sized objects. Whippet doesn’t do that either, instead relying on such failure to allocate in a block to cause fragmentation and thus hurry along the process of compaction.
Whippet vs Immix: Lazy sweeping
Immix: “cheap” eager coarse sweep
Whippet: just-in-time lazy fine-grained sweep
Corrolary: Data computed by sweep available when sweep complete
Live data at previous GC only known before next GC
Empty blocks discovered by sweeping
Having a fine-grained line mark array means that it’s no longer a win to do an eager sweep of all blocks after collecting. Instead Whippet applies the classic “lazy sweeping” optimization to make mutators sweep their blocks just before allocating into them. This introduces a delay in the collection algorithm: Whippet doesn’t find out about e.g. fragmentation until the whole heap is swept, but by the time we fully sweep the heap, we’ve exhausted it via allocation. It introduces a different flavor to the GC, not entirely unlike original Immix, but foreign.
Whippet vs BDW
Compaction/defrag/pinning, heap shrinking, sticky-mark generational GC, threads/contention/allocation, ephemerons, precision, tools
Right! With that out of the way, let’s talk about what Whippet gives to Guile, relative to BDW-GC.
Whippet vs BDW: Motion
Heap-conservative tracing: no object moveable
Stack-conservative tracing: stack referents pinned, others not
Whippet: If whole-heap fragmentation exceeds threshold, evacuate most-fragmented blocks
Stack roots scanned first; marked instead of evacuated, implicitly pinned
Explicit pinning: bit in mark byte
If all edges in the heap are conservative, then you can’t move anything, because you don’t know if an edge is a pointer that can be updated or just a spicy integer. But most systems aren’t actually like this: you have conservative edges from the stack, but you can precisely enumerate intra-object edges on the heap. In that case, you have a known set of conservative edges, and you can simply visit those edges first, marking their referents in place instead of evacuating. (Marking an object instead of evacuating implicitly pins it for the duration of the current GC cycle.) Then you visit heap edges precisely, possibly evacuating objects.
I should note that Whippet has a bit in the mark byte for use in explicitly pinning an object. I’m not sure how to manage who is responsible for setting that bit, or what the policy will be; the current idea is to set it for any object whose identity-hash value is taken. We’ll see.
Whippet vs BDW: Shrinking
Lazy sweeping finds empty blocks: potentially give back to OS
Need empty blocks? Do evacuating collection
Possibility to do http://marisa.moe/balancer.html
With the BDW collector, your heap can only grow; it will never shrink (unless you enable a non-default option and you happen to have verrry low fragmentation). But with Whippet and evacuation, we can rearrange objects so as to produce empty blocks, which can then be returned to the OS if so desired.
In one of my microbenchmarks I have the system allocating long-lived data, interspersed with garbage (objects that are dead after allocation) whose size is in a power-law distribution. This should produce quite some fragmentation, eventually, and it does. But then Whippet decides to defragment, and it works great! Since Whippet doesn’t keep a whole 2x reserve like a semi-space collector, it usually takes more than one GC cycle to fully compact the heap; usually about 3 cycles, from what I can see. I should do some more measurements here.
Of course, this is just mechanism; choosing the right heap sizing policy is a different question.
wingolog.org/archives/2022/10/22/the-sticky-mark-bit-algorithm
Card marking barrier (256B); compare to BDW mprotect / SIGSEGV
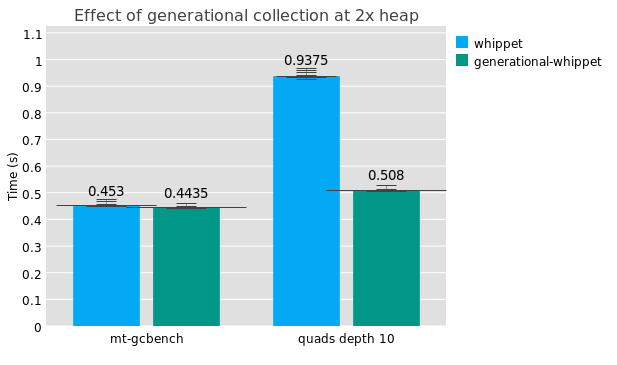
The Boehm collector also has a non-default mode in which it uses mprotect and a SIGSEGV handler to enable sticky-mark-bit generational collection. I haven’t done a serious investigation, but I see it actually increasing run-time by 20% on one of my microbenchmarks that is actually generation-friendly. I know that Azul’s C4 collector used to use page protection tricks but I can only assume that BDW’s algorithm just doesn’t work very well. (BDW’s page barriers have another purpose, to enable incremental collection, in which marking is interleaved with allocation, but this mode is off if parallel markers are supported, and I don’t know how well it works.)
Anyway, it seems we can do better. The ideal would be a semi-space nursery, which is the usual solution, but because of conservative roots we are limited to the sticky mark-bit algorithm. Some benchmarks aren’t very generation-friendly; the first pair of bars in the chart above shows the mt-gcbench microbenchmark running with and without generational collection, and there’s no difference. But in the second, for the quads benchmark, we see a 2x speedup or so.
Of course, to get generational collection to work, we require mutators to use write barriers, which are little bits of code that run when an object is mutated that tell the GC where it might find links from old objects to new objects. Right now in Guile we don’t do this, but this benchmark shows what can happen if we do.
Whippet vs BDW: Scale
BDW: TLS segregated-size freelists, lock to refill freelists, SIGPWR for stop
Whippet: thread-local block, sweep without contention, wait-free acquisition of next block, safepoints to stop with ragged marking
Both: parallel markers
Another thing Whippet can do better than BDW is performance when there are multiple allocating threads. The Immix heap organization facilitates minimal coordination between mutators, and maximum locality for each mutator. Sweeping is naturally parallelized according to how many threads are allocating. For BDW, on the other hand, every time an mutator needs to refill its thread-local free lists, it grabs a global lock; sweeping is lazy but serial.
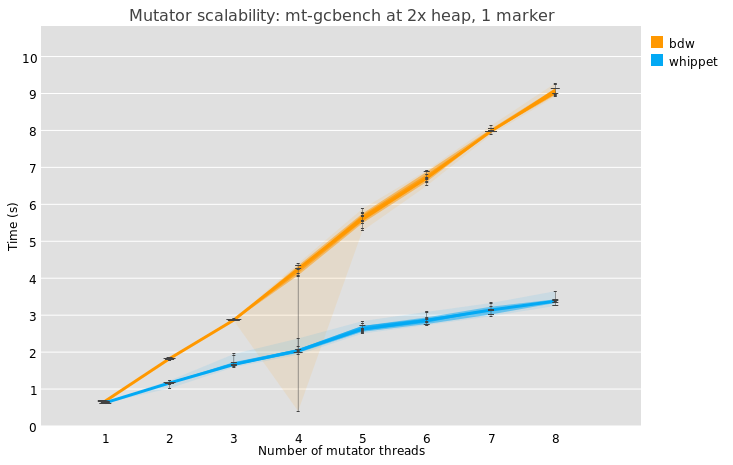
Here’s a chart showing whippet versus BDW on one microbenchmark. On the X axis I add more mutator threads; each mutator does the same amount of allocation, so I’m increasing the heap size also by the same factor as the number of mutators. For simplicity I’m running both whippet and BDW with a single marker thread, so I expect to see a linear increase in elapsed time as the heap gets larger (as with 4 mutators there are roughly 4 times the number of live objects to trace). This test is run on a Xeon Silver 4114, taskset to free cores on a single socket.
What we see is that as I add workers, elapsed time increases linearly for both collectors, but more steeply for BDW. I think (but am not sure) that this is because whippet effectively parallelizes sweeping and allocation, whereas BDW has to contend over a global lock to sweep and refill free lists. Both have the linear factor of tracing the object graph, but BDW has the additional linear factor of sweeping, whereas whippet scales with mutator count.
Incidentally you might notice that at 4 mutator threads, BDW randomly crashed, when constrained to a fixed heap size. I have noticed that if you fix the heap size, BDW sometimes (and somewhat randomly) fails. I suspect the crash due to fragmentation and inability to compact, but who knows; multiple threads allocating is a source of indeterminism. Usually when you run BDW you let it choose its own heap size, but for these experiments I needed to have a fixed heap size instead.
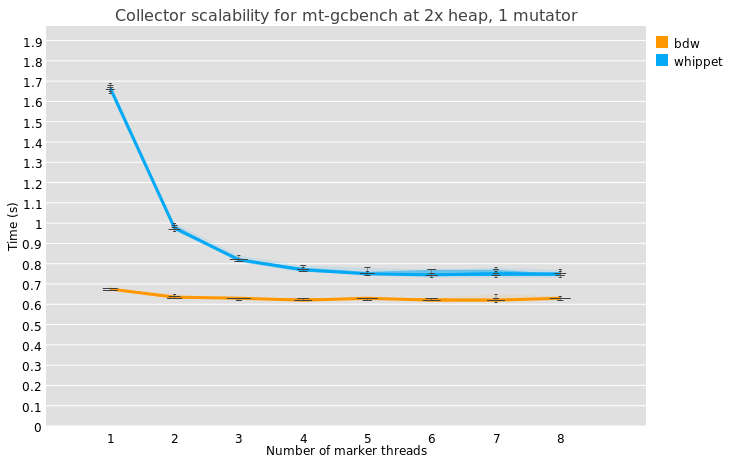
Another measure of scalability is, how does the collector do as you add marker threads? This chart shows that for both collectors, runtime decreases as you add threads. It also shows that whippet is significantly slower than BDW on this benchmark, which is Very Weird, and I didn’t have access to the machine on which these benchmarks were run when preparing the slides in the train... so, let’s call this chart a good reminder that Whippet is a WIP :)
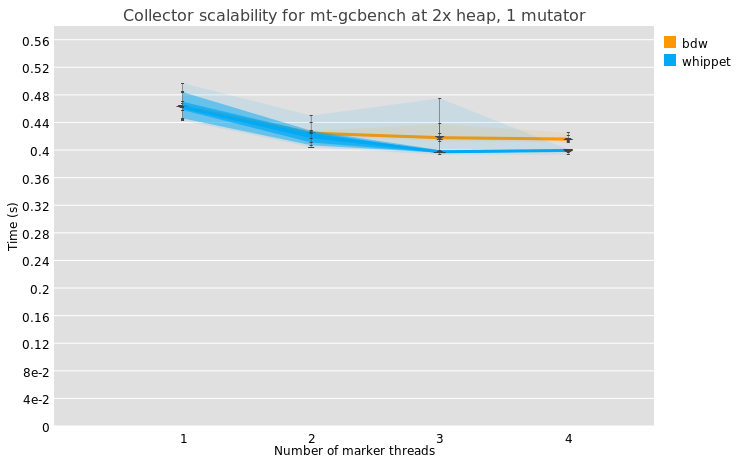
While in the train to Brussels I re-ran this test on the 4-core laptop I had on hand, and got the results that I expected: that whippet performed similarly to BDW, and that adding markers improved things, albeit marginally. Perhaps I should look on a different microbenchmark.
Incidentally, when you configure Whippet for parallel marking at build-time, it uses a different implementation of the mark stack when compared to the parallel marker, even when only 1 marker is enabled. Certainly the parallel marker could use some tuning.
Whippet vs BDW: Ephemerons
BDW: No ephemerons
Whippet: Yes
Another deep irritation I have with BDW is that it doesn’t support ephemerons. In Guile we have a number of facilities (finalizers, guardians, the symbol table, weak maps, et al) built on what BDW does have (finalizers, weak references), but the implementations of these facilities in Guile are hacky, slow, sometimes buggy, and don’t compose (try putting an object in a guardian and giving it a finalizer to see what I mean). It would be much better if the collector API supported ephemerons natively, specifying their relationship to finalizers and other facilities, allowing us to build what we need in terms of those primitives. With our own GC, we can do that, and do it in such a way that it doesn’t depend on the details of the specific collection algorithm. The exception of course is that as BDW doesn’t support ephemerons per se, what we get is actually a weak-key association instead, whose value can keep the key alive. Oh well, it’s no worse than the current situation.
Whippet vs BDW: Precision
BDW: ~Always stack-conservative, often heap-conservative
Whippet: Fully configurable (at compile-time)
Guile in mid/near-term: C stack conservative, Scheme stack precise, heap precise
Possibly fully precise: unlock semi-space nursery
Conservative tracing is a fundamental design feature of the BDW collector, both of roots and of inter-heap edges. You can tell BDW how to trace specific kinds of heap values, but the default is to do a conservative scan, and the stack is always scanned conservatively. In contrast, these tradeoffs are all configurable in Whippet. You can scan the stack and heap precisely, or stack conservatively and heap precisely, or vice versa (though that doesn’t make much sense), or both conservatively.
The long-term future in Guile is probably to continue to scan the C stack conservatively, to continue to scan the Scheme stack precisely (even with BDW-GC, the Scheme compiler emits stack maps and installs a custom mark routine), but to scan the heap as precisely as possible. It could be that a user uses some of our hoary ancient APIs to allocate an object that Whippet can’t trace precisely; in that case we’d have to disable evacuation / object motion, but we could still trace other objects precisely.
If Guile ever moved to a fully precise world, that would be a boon for performance, in two ways: first that we would get the ability to use a semi-space nursery instead of the sticky-mark-bit algorithm, and relatedly that we wouldn’t need to initialize mark bytes when allocating objects. Second, we’d gain the option to use must-move algorithms for the old space as well (mark-compact, semi-space) if we wanted to. But it’s just an option, one that that Whippet opens up for us.
Whippet vs BDW: Tools?
Can build heap tracers and profilers moer easily
More hackable
(BDW-GC has as many preprocessor directives as whippet has source lines)
Finally, relative to BDW-GC, whippet has a more intangible advantage: I can actually hack on it. Just as an indication, 15% of BDW source lines are pre-processor directives, and there is one file that has like 150 #ifdef‘s, not counting #elseif’s, many of them nested. I haven’t done all that much to BDW itself, but I personally find it excruciating to work on.
Hackability opens up the possibility to build more tools to help us diagnose memory use problems. They aren’t in Whippet yet, but there can be!
Engineering Whippet
Embed-only, abstractions, migration, modern; timeline
OK, that rounds out the comparison between BDW and Whippet, at least on a design level. Now I have a few words about how to actually get this new collector into Guile without breaking the bug budget. I try to arrange my work areas on Guile in such a way that I spend a minimum of time on bugs. Part of my strategy is negligence, I will admit, but part also is anticipating problems and avoiding them ahead of time, even if it takes more work up front.
Engineering Whippet: Embed-only
Semi: 6 kB; Whippet: 22 kB; BDW: 184 kB
Compile-time specialization:
- for embedder (e.g. how to forward objects)
- for selected GC algorithm (e.g. semi-space vs whippet)
Built apart, but with LTO to remove library overhead
So the BDW collector is typically shipped as a shared library that you dynamically link to. I should say that we’ve had an overall good experience with upgrading BDW-GC in the past; its maintainer (Ivan Maidanski) does a great and responsible job on a hard project. It’s been many, many years since we had a bug in BDW-GC. But still, BDW is dependency, and all things being equal we prefer to remove moving parts.
The approach that Whippet is taking is to be an embed-only library: it’s designed to be compiled into your project. It’s not an include-only library; it still has to be compiled, but with link-time-optimization and a judicious selection of fast-path interfaces, Whippet is mostly able to avoid abstractions being a performance barrier.
The result is that Whippet is small, both in source and in binary, which minimizes its maintenance overhead. Taking additional stripped optimized binary size as the metric, by my calculations a semi-space collector (with a large object space and ephemeron support) takes about 6 kB of object file size, whereas Whippet takes 22 and BDW takes 184. Part of how Whippet gets so small is that it is is configured in major ways at compile-time (choice of main GC algorithm), and specialized against the program it’s embedding against (e.g. how to patch in a forwarding pointer). Having all API being internal and visible to LTO instead of going through ELF symbol resolution helps in a minor way as well.
Engineering Whippet: Abstract performance
User API abstracts over GC algorithm, e.g. semi-space or whippet
Expose enough info to allow JIT to open-code fast paths
Inspired by mmtk.io
Abstractions permit change: of algorithm, over time
From a composition standpoint, Whippet is actually a few things. Firstly there is an abstract API to make a heap, create per-thread mutators for a heap, and allocate objects for a mutator. There is the aforementioned embedder API, for having the embedding program indicate how to trace objects and install forwarding pointers. Then there is some common code (for example ephemeron support). There are implementations of the different spaces: semi-space, large object, whippet/immix; and finally collector implementations that tie together the spaces into a full implementation of the abstract API. (In practice the more iconic spaces are intertwingled with the collector implementations they define.)
I don’t think I would have gone down this route without seeing some prior work, for example libpas, but it was really MMTk that convinced me that it was worth spending a little time thinking about the GC not as a structureless blob but as a system made of parts and exposing a minimal interface. In particular, I was inspired by seeing that MMTk is able to get good performance while also being abstract, exposing representation details such as how to tell a JIT compiler about allocation fast-paths, but in a principled way. So, thanks MMTk people, for this and so many things!
I’m particularly happy that the API is abstract enough that it frees up not only the garbage collector to change implementations, but also Guile and other embedders, in that they don’t have to bake in a dependency on specific collectors. The semi-space collector has been particularly useful here in ensuring that the abstractions don’t accidentally rely on support for object pinning.
Engineering Whippet: Migration
API implementable by BDW-GC (except ephemerons)
First step for Guile: BDW behind Whippet API
Then switch to whippet/immix (by default)
The collector API can actually be implemented by the BDW collector. Whippet includes a collector that is a thin wrapper around the BDW API, with support for fast-path allocation via thread-local freelists. In this way we can always check the performance of any given collector against an external fixed point (BDW) as well as a theoretically known point (the semi-space collector).
Indeed I think the first step for Guile is precisely this: refactor Guile to allocate through the Whippet API, but using the BDW collector as the implementation. This will ensure that the Whippet API is sufficient, and then allow an incremental switch to other collectors.
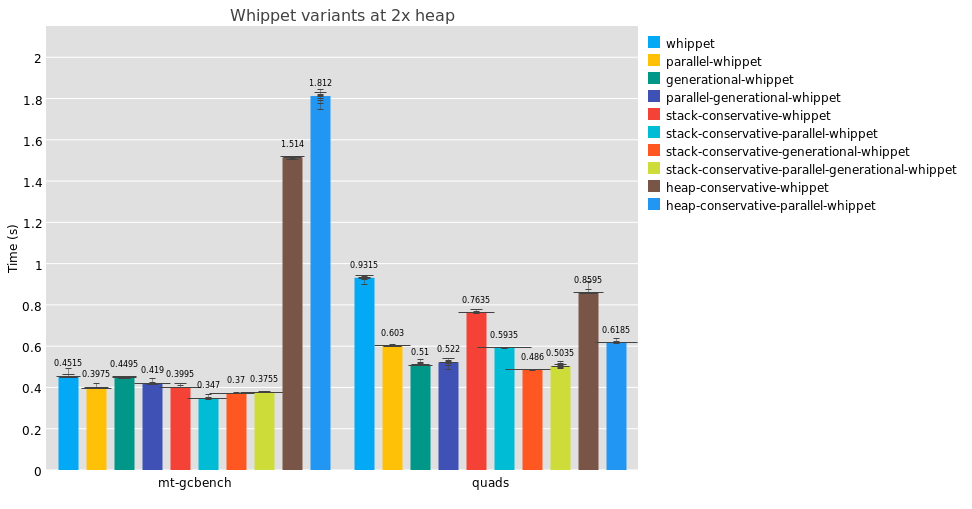
Incidentally, when it comes to integrating Whippet, there are some choices to be made. I mentioned that it’s quite configurable, and this chart can give you some idea. On the left side is one microbenchmark (mt-gcbench) and on the right is another (quads). The first generates a lot of fragmentation and has a wide range of object sizes, including some very large objects. The second is very uniform and many allocations die young.
(I know these images are small; right-click to open in new tab or pinch to zoom to see more detail.)
Within each set of bars we have 10 different scenarios, corresponding to different Whippet configurations. (All of these tests are run on my old 4-core laptop with 4 markers if parallel marking is supported, and a 2x heap.)
The first bar in each side is serial whippet: one marker. Then we see parallel whippet: four markers. Great. Then there’s generational whippet: one marker, but just scanning objects allocated in the current cycle, hoping that produces enough holes. Then generational parallel whippet: the same as before, but with 4 markers.
The next 4 bars are the same: serial, parallel, generational, parallel-generational, but with one difference: the stack is scanned conservatively instead of precisely. You might be surprised but all of these configurations actually perform better than their precise counterparts. I think the reason is that the microbenchmark uses explicit handle registration and deregistration (it’s a stack) instead of compiler-generated stack maps in a side table, but I’m not precisely (ahem) sure.
Finally the next 2 bars are serial and parallel collectors, but marking everything conservatively. I have generational measurements for this configuration but it really doesn’t make much sense to assume that you can emit write barriers in this context. These runs are slower than the previous configuration, mostly because there are some non-pointer locations that get scanned conservatively that wouldn’t get scanned precisely. I think conservative heap scanning is less efficient than precise but I’m honestly not sure, there are some instruction locality arguments in the other direction. For mt-gcbench though there’s a big array of floating-point values that a precise scan will omit, which causes significant overhead there. Probably for this configuration to be viable Whippet would need the equivalent of BDW’s API to allocate known-pointerless objects.
Engineering Whippet: Modern
stdatomic
constexpr-ish
pthreads (for parallel markers)
No void*; instead struct types: gc_ref, gc_edge, gc_conservative_ref, etc
Embed-only lib avoids any returns-struct-by-value ABI issue
Rust? MMTk; supply chain concerns
Platform abstraction for conservative root finding
I know it’s a sin, but Whippet is implemented in C. I know. The thing is, in the Guile context I need to not introduce wild compile-time dependencies, because of bootstrapping. And I know that Rust is a fine language to use for GC implementation, so if that’s what you want, please do go take a look at MMTk! It’s a fantastic project, written in Rust, and it can just slot into your project, regardless of the language your project is written in.
But if what you’re looking for is something in C, well then you have to pick and choose your C. In the case of Whippet I try to use the limited abilities of C to help prevent bugs; for example, I generally avoid void* and instead wrap pointers or addresses into single-field structs that can’t be automatically cast, for example to prevent a struct gc_ref that denotes an object reference (or NULL; it’s an option type) from being confused with a struct gc_conservative_ref, which might not point to an object at all.
(Of course, by “C” I mean “C as compiled by gcc and clang with -fno-strict-aliasing”. I don’t know if it’s possible to implement even a simple semi-space collector in C without aliasing violations. Can you access a Foo* object within a mmap‘d heap through its new address after it has been moved via memcpy? Maybe not, right? Thoughts are welcome.)
As a project written in the 2020s instead of the 1990s, Whippet gets to assume a competent C compiler, for example relying on the compiler to inline and fold branches where appropriate. As in libpas, Whippet liberally passes functions as values to inline functions, and relies on the compiler to boil away function calls. Whippet only uses the C preprocessor when it absolutely has to.
Finally, there is a clean abstraction for anything that’s platform-specific, for example finding the current stack bounds. I haven’t compiled this code on Windows or MacOS yet, but I am not anticipating too many troubles.
Engineering Whippet: Timeline
As time permits
Whippet TODO: heap growth/shrinking, finalizers, safepoint API
Guile TODO: safepoints; heap-conservative first
Precise heap TODO: gc_trace_object, SMOBs, user structs with raw ptr fields, user gc_malloc usage; 3.2
6 months for 3.1.1; 12 for 3.2.0 ?
So where does this get us? Where are we now?
For Whippet itself, I think it’s mostly done – enough to start shifting focus to some different phase. It’s missing some needed features, notably the ability to grow the heap at all, as I’ve been in fixed-heap-size-only mode during development. It’s also missing finalizers. And, something needs to be done to unify Guile’s handling of safepoints and processing of asynchronous signals with Whippet’s need to stop all mutators. Some details remain.
But, I think we are close to ready to start integrating in Guile. At first this is just porting Guile to use the Whippet API to access BDW instead of using BDW directly. This whole thing is a side project for me that I work on when I can, so it doesn’t exactly proceed at full pace. Perhaps this takes 6 months. Then we can cut a new unstable release, and hopefully release 3.2 withe support for the Immix-flavored collector in another 6 or 9 months.
I thought that we would be forced to make ABI changes, if only because of some legacy APIs assume conservative tracing of object contents. But after a discussion at FOSDEM with Carlo Piovesan I realized this isn’t true: because the decision to evacuate or not is made on a collection-by-collection basis, I could simply disable evacuation if the user ever uses a facility that might prohibit object motion, for example if they ever define a SMOB type. If the user wants evacuation, they need to be more precise with their data types, but either way Guile is ready.
Whippet: A Better GC?
An Immix-derived GC
https://wingolog.org/tags/gc/
Guile 3.2 ?
Thanks to MMTk authors for inspiration!
And that’s it! Thanks for reading all the way here. Comments are quite welcome.
As I mentioned in the very beginning, this talk was really about Whippet in the context of Guile. There is a different talk to be made about Guile+Whippet versus other language implementations, for example those with concurrent marking or semi-space nurseries or the like. Yet another talk is Whippet in the context of other GC algorithms. But this is a start. It’s something I’ve been working on for a while now already and I’m pleased that it’s gotten to a point where it seems to be at least OK, at least an improvement with respect to BDW-GC in some ways.
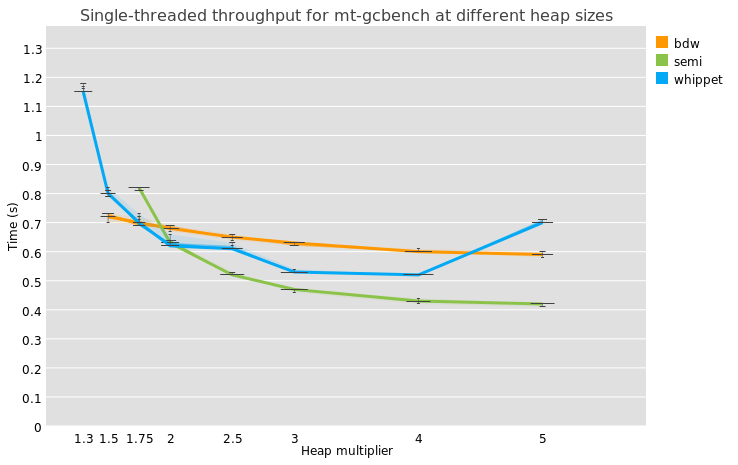
But before leaving you, another chart, to give a more global idea of the state of things. Here we compare a single mutator thread performing a specific microbenchmark that makes trees and also lots of fragmentation, across three different GC implementations and a range of heap sizes. The heap size multipliers in this and in all the other tests in this post are calculated analytically based on what the test thinks its maximum heap size should be, not by measuring minimum heap sizes that work. This size is surely lower than the actual maximum required heap size due to internal fragmentation, but the tests don’t know about this.
The three collectors are BDW, a semi-space collector, and whippet. Semi-space manages to squeeze in less than 2x of a heap multiplier because it has (and whippet has) a separate large object space that isn’t ever evacuated.
What we expect is that tighter heaps impose more GC time, and indeed we see that times are higher on the left side than the right.
Whippet is the only implementation that manages to run at a 1.3x heap, but it takes some time. It’s slower than BDW at a 1.5x heap but better there on out, until what appears to be a bug or pathology makes it take longer at 5x. Adding memory should always decrease run time.
The semi-space collector starts working at 1.75x and then surpasses all collectors from 2.5x onwards. We expect the semi-space collector to win for big heaps, because its overhead is proportional to live data only, whereas mark-sweep and mark-region collectors have to sweep, which is proportional to heap size, and indeed that’s what we see.
I think this chart shows we have some tuning yet to do. The range between 2x and 3x is quite acceptable, but we need to see what’s causing Whippet to be slower than BDW at 1.5x. I haven’t done as much performance tuning as I would like to but am happy to finally be able to know where we stand.
And that’s it! Happy hacking, friends, and may your heap sizes be ever righteous.