whippet progress update: feature-complete!
Greetings, gentle readers. Today, an update on recent progress in the Whippet embeddable garbage collection library.
feature-completeness
When I started working on Whippet, two and a half years ago already, I was aiming to make a new garbage collector for Guile. In the beginning I was just focussing on proving that it would be advantageous to switch, and also learning how to write a GC. I put off features like ephemerons and heap resizing until I was satisfied with the basics.
Well now is the time: with recent development, Whippet is finally feature-complete! Huzzah! Now it’s time to actually work on getting it into Guile. (I have some performance noodling to do before then, adding tracing support, and of course I have lots of ideas for different collectors to build, but I don’t have any missing features at the current time.)
heap resizing
When you benchmark a garbage collector (or a program with garbage collection), you generally want to fix the heap size. GC overhead goes down with more memory, generally speaking, so you don’t want to compare one collector at one size to another collector at another size.
(Unfortunately, many (most?) benchmarks of dynamic language run-times and the programs that run on them fall into this trap. Imagine you are benchmarking a program before and after a change. Automatic heap sizing is on. Before your change the heap size is 200 MB, but after it is 180 MB. The benchmark shows the change to regress performance. But did it really? It could be that at the same heap size, the change improved performance. You won’t know unless you fix the heap size.)
Anyway, Whippet now has an implementation of MemBalancer. After every GC, we measure the live size of the heap, and compute a new GC speed, as a constant factor to live heap size. Every second, in a background thread, we observe the global allocation rate. The heap size is then the live data size plus the square root of the live data size times a factor. The factor has two components. One is constant, the expansiveness of the heap: the higher it is, the more room the program has. The other depends on the program, and is computed as the square root of the ratio of allocation speed to collection speed.
With MemBalancer, the heap ends up getting resized at every GC, and via the heartbeat thread. During the GC it’s easy because it’s within the pause; no mutators are running. From the heartbeat thread, mutators are active: taking the heap lock prevents concurrent resizes, but mutators are still consuming empty blocks and producing full blocks. This works out fine in the same way that concurrent mutators is fine: shrinking takes blocks from the empty list one by one, atomically, and returns them to the OS. Expanding might reclaim paged-out blocks, or allocate new slabs of blocks.
However, even with some exponentially weighted averaging on the speed observations, I have a hard time understanding whether the algorithm is overall a good thing. I like the heartbeat thread, as it can reduce memory use of idle processes. The general square-root idea sounds nice enough. But adjusting the heap size at every GC feels like giving control of your stereo’s volume knob to a hyperactive squirrel.
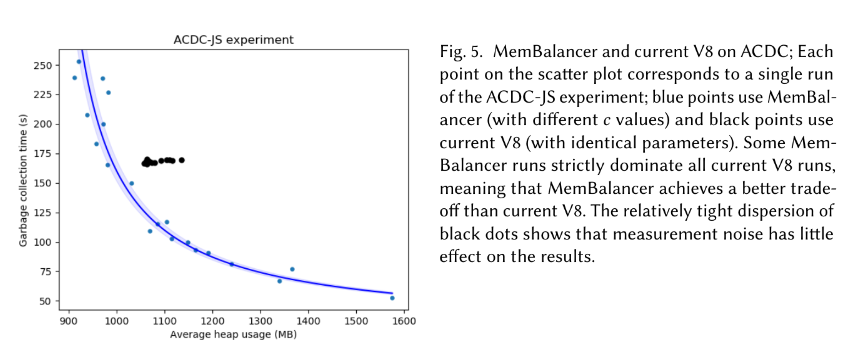
Furthermore, the graphs in the MemBalancer paper are not clear to me: the paper claims more optimal memory use even in a single-heap configuration, but the x axis of the graphs is “average heap size”, which I understand to mean that maximum heap size could be higher than V8’s maximum heap size, taking into account more frequent heap size adjustments. Also, some measurement of total time would have been welcome, in addition to the “garbage collection time” on the paper’s y axis; there are cases where less pause time doesn’t necessarily correlate to better total times.
deferred page-out
Motivated by MemBalancer’s jittery squirrel, I implemented a little queue for use in paging blocks in and out, for the mmc and pcc collectors: blocks are quarantined for a second or two before being returned to the OS via madvise(MADV_DONTNEED). That way if you release a page and then need to reacquire it again, you can do so without bothering the kernel or other threads. Does it matter? It seems to improve things marginally and conventional wisdom says to not mess with the page table too much, but who knows.
mmc rename
Relatedly, Whippet used to be three things: the project itself, consisting of an API and a collection of collectors; one specific collector; and one specific space within that collector. Last time I mentioned that I renamed the whippet space to the nofl space. Now I finally got around to renaming what was the whippet collector as well: it is now the mostly-marking collector, or mmc. Be it known!
Also as a service note, I removed the “serial copying collector” (scc). It had the same performance as the parallel copying collector with parallelism=1, and pcc can be compiled with GC_PARALLEL=0 to explicitly choose the simpler serial grey-object worklist.
per-object pinning
The nofl space has always supported pinned objects, but it was never exposed in the API. Now it is!
Of course, collectors with always-copying spaces won’t be able to pin objects. If we want to support use of these collectors with embedders that require pinning, perhaps because of conservative root scanning, we’d need to switch to some kind of mostly-copying algorithm.
safepoints without allocation
Another missing feature was a safepoint API. It hasn’t been needed up to now because my benchmarks all allocate, but for programs that have long (tens of microseconds maybe) active periods without allocation, you want to be able to stop them without waiting too long. Well we have that exposed in the API now.
removed ragged stop
Following on my article on ragged stops, I removed ragged-stop marking from mmc, for a nice net 180 line reduction in some gnarly code. Speed seems to be similar.
next up: tracing
And with that, I’m relieved to move on to the next phase of Whippet development. Thanks again to NLnet for their support of this work. Next up, adding fine-grained tracing, so that I can noodle a bit on performance. Happy allocating!
Comments are closed.