a closer look at crankshaft, v8's optimizing compiler
Continuing in my series of articles on V8, Google's JavaScript engine, in this article I'd like to take a closer look at V8's optimizing compiler, with a focus on the Hydrogen intermediate language.
brief summary
As my readers might recall, Crankshaft is the marketing name of V8's optimizing compiler. It complements the "full" compiler by optimizing hot functions, while ignoring uncommon cases. It translates the JavaScript abstract syntax tree to a high-level static single-assignment (SSA) representation called Hydrogen, and tries to optimize that Hydrogen graph. Then the Hydrogen is translated to the machine-specific Lithium low-level language, which facilitates register allocation and, finally, code generation.
The point of the Hydrogen translation is threefold:
To permit inlining. Inlining is truly the mother of all optimizations, in that it permits more optimizations to occur.
To permit temporary values to be represented as untagged integer or double values. In JavaScript, you need type feedback to do this with any degree of success. Unboxing reduces memory pressure and permits Crankshaft to use efficient native machine instructions. But as you would expect, this unboxing needs to be done carefully.
To facilitate loop-invariant code motion and common subexpression elimination.
The Hydrogen SSA representation facilitates all of these operations. This article takes a closer look at how it does so.
static single assignment

(click for accessible SVG)
Hydrogen consists of values--instructions and phis--contained in basic blocks, which themselves are contained in a graph.

The standard SSA notation associates a named value with every expression:
t1 = x + y; t2 = 3; t3 = t1 + t2; ...
It's useful to write it out this way, but these temporary names are not strictly necessary: since each instruction defines a temporary, we can use the identity (address) of each instruction as its name, for the purpose of SSA.

A later pass will allocate storage for all of these temporaries -- on the stack, on the heap, or unboxed in general-purpose or SSE/Neon registers. At first I was quite confused about the term "instruction", as we functional programmers tend to use "expression", but it's something you get used to after a while, and it's useful when you use it to refer to the named definition in addition to the expression that produces it.

An instruction is a kind of value -- an entity that defines a name. There other kind of value is the phi. Phis occur at control-flow joins, and are logically associated with the beginning of a block. My previous article discusses phis in detail.
All values have a pointer to their containing block and to their uses. A use is when a later instruction uses the value computed (defined) by an earlier instruction. Values also have a pointer to the next instruction in their block. It is cheaper to traverse instructions forward, in the direction of control and data flow, than it is to go backward. Values also have fields for their type, their representation, a flags bitfield, and a pointer to a range structure. We will look at these in more detail later.

The last instruction in a block is a control instruction. No one uses the value defined by a control expression -- their purpose is to transfer control to another basic block. The set of possible blocks that may follow a block in control-flow order are the successors of a block. Preceding blocks are predecessors. Every block has an array of pointers to its predecessors and successors, and also to its dominator block, and to all the blocks that it dominates.
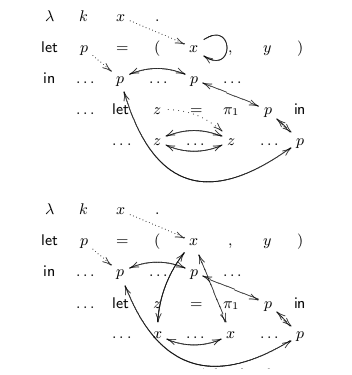
Now, friends, when I first saw this I was disgusted. What a rat's nest of pointers! But then I read Kennedy's great Compiling With Continuations, Continued paper and it became clear that it is very difficult to have an efficient functional-style intermediate representation. The diagrams above are from a part of his paper in which he suggests a mutable IR. In my opinion, if he's gone that far, he might as well finish the job and eliminate temporary identifiers entirely, as Hydrogen does.
electrolysis
Crankshaft has a funny job to do. Not only does it have to optimize JavaScript, which is hard enough; it also has to do so in a way that permits on-stack replacement to optimize a long-running loop, without exiting the loop.
In practice what this means is that Crankshaft needs to walk the abstract syntax tree (AST) to emit Hydrogen code in the same way as the full compiler. It needs to simulate what the full compiler is doing: what is on the stack, which variables are heap-allocated and which are not, and, for named local variables, what HValue is bound to that variable. This simulation is kept in an environment.
This AST-to-Hydrogen translation process also handles phi insertion. So unlike the textbook dominance-frontier algorithm for optimal phi insertion, the HGraphBuilder simply adds phi values whenever a block has more than one predecessor, for every variable in the environment that is not always bound to the same value. For loops, a phi is added for every variable live in the environment at that time. A later pass attempts to prune the number of phis, where it can.
type feedback
The AST that was given to the crankshaft compiler has integer identifiers assigned to each node. These identifiers are assigned predictably, so they are the same identifiers that the "full-codegen" compiler saw, and they are embedded in the inline caches used by the full-codegen code. This correspondence allows crankshaft to know the types of the values that have been seen at any given call site, property access, etc.
This information is used by the graph builder to initialize the type field of each HValue, to help in type inference. Additionally, property accesses and function calls can record the precise type of object being accessed, or the function that was called, so that Crankshaft has an opportunity to inline these function and method calls.
inlining
When the graph builder reaches a call, it can try to inline it. Note that this happens very early, before any optimizations are made on the source code. This allows the optimizations to have more visibility, and allows for more code motion. (In general, V8 will not move instructions across a call boundary.)
There are lots of heuristics and conditions that affect inlining, and these are in flux. Some conditions that must currently be met for inlining to proceed are:
The function to be inlined is less than 600 characters long.
Neither the inner nor the outer functions may contain heap-allocated variables. (In practice, this means that neither function may contain lexical closures.)
Inlining of for-in, with, and some other expression types is not currently supported.
There is a limit on the maximum inlining depth.
A function's call to itself will not be inlined.
There is a limit to the number of nodes added to the AST.
source-to-source optimization passes
As parsing proceeds, Crankshaft generates specific HInstruction nodes and packs them into HBasicBlocks. There is a large set of about 120 instructions, which allows Crankshaft to reason precisely about the various operations and their representations.
At this point, inlining is complete, so Crankshaft moves to focus on representation of temporary values. The goal is to unbox as many values as possible, allowing the use of native machine instructions, and decreasing the allocation rate of tagged doubles. The Hydrogen SSA language directly facilitates this control-flow and data-flow analysis.
The following sections discuss the various source-to-source passes that are made on the Hydrogen IR. It's a lot of detail, but I'm sure that someone will find it useful.
block reordering
Crankshaft reorders the array of blocks in the HGraph to appear in reverse post-order, equivalent to a topological sort. In this way, iterating the array of blocks from beginning to end traverses them in data-flow order.
dominator assignment
The reverse post-order sort from the previous step facilitates calculation of the dominator for each block. The entry block dominates its successors. Other blocks are iterated over, in order, assigning them the dominator of their predecessors, or the common dominator of their predecessors if there is more than one.
mark dead subgraphs
It can often be the case that a function being optimized does not have full type information. Some branches in the original function may never have been executed, and so code on those branches does not have any type feedback. If the parser reaches such a branch -- and it will know at parse-time, because that's when it has the type-feedback information -- then it inserts an unconditional soft deoptimization, to force the collection of more type information, should that branch be reached in optimized code.
However, instead of causing a branch to a terminal deoptimization block, the parse continues, presumably because Crankshaft needs to proceed with its abstract interpretation of the AST. For that reason, the soft deoptimization appears in the instruction stream, not as the last instruction in the block.
To avoid the compiler wasting its time trying to optimize loops and move code in parts of the graph that have never been reached, this dead-subgraph pass puts a mark on all blocks dominated by a block containing an unconditional soft deoptimization. As you can see, this analysis is facilitated by the SSA dominator relation.
redundant phi elimination
The naïve phi placement algorithm detailed above can put phis where they are not needed. This pass eliminates phi values whose input is always the same, replacing the uses with the use of the value.
Like a number of phi-centered optimizations, elimination of one phi can expose other phis for elimination. For this reason, this and many other algorithms use a worklist.
In this case, all phis are placed on a work list. Then, while there are any phis on the worklist, a phi is taken off the list, and if it is eliminatable, it is replaced. Now here's the trick: if the phi was in turn used by any other phi, the phi uses are pushed onto the list, if they weren't there already. Iteration proceeds until the worklist is empty.
To keep the big-O order of worklist operations down, you need a flag for each element indicating whether the element is already in the list. The bit should either be in the objects being traversed, or in a separate bitvector. In this particular case -- and in this case only, as far as I can tell -- there is no such bit, so the algorithm can take too much time, in certain cases.
dead phi elimination, and phi collection
Some phi values are dead, having no real uses, neither direct nor indirect (through some other phi). This pass eliminates any phi that doesn't have a real use. It's somewhat like a garbage collection algorithm, and also uses a worklist.
Once this pass has run, we have minimized the set of phis, so we can collect them all into an array and assign them indices. These indices can be used in the future bitvectors, to contain worklist-driven algorithms.
As the phis are collected, if any undefined value is found to reach a phi, or arguments can reach a phi only via some inputs, then optimization is aborted entirely.
representation inference
Every HValue has a type field, representing a coarse approximation of the types seen at a particular AST node, and a representation field, representing a specific choice of how to represent a value. The goal, as I have said, is to represent temporaries as untagged int32 or double values. Type and representation are related, but they are treated separately in Crankshaft. This pass is about representation inference.
Firstly, Crankshaft looks at all of the phis, and sees which ones are connected. This is an N2 fixed-point iteration. Then, for each phi, if any operand of the phi or any connected phi may not be converted to an int32, Crankshaft pessimistically marks the phi as not convertible to an int32. This pass tries to prevent too many representation changes for phi values.
Finally, for all values with flexible representation--phis, Math.abs, and binary bitwise and arithmetic operations--Crankshaft determines the representation to use for that value. If the representation can be inferred directly from the inputs, then that representation is used. Otherwise, some heuristics are run on the representations needed by the use sites of the value. If all uses are untagged, then the representation will be untagged, as an int32 if possible, unless any use treats the value as a double.
The end result is that, hopefully, many values have been unboxed to int32 or double values.
range analysis
This pass looks at each value, and tries to determine its range, if Crankshaft was actually able to allocate a specialized representation for it. In practice this is mainly used for values represented as integers. It allows HInstructions to assert various properties about the instruction, such as lack of overflow, or lack of negative zero values. These properties can influence code generation.
The algorithm propagates constraints forward on all control paths, so that control instructions can produce different ranges for the same value on different control paths. Ranges reaching a phi node are unioned together.
type inference and canonicalization
I mentioned that representation was related to type. Here I should be more specific. In Crankshaft, types are logically associated with objects. One can treat any object as an array, for the purposes of a calculation, but that treatment does not coerce the object itself to another type. Representation is about how to use an object; type is about the object itself.
Type inference can help eliminate runtime checks. If we can infer that a certain value is not only a tagged value, but is not a smi (small integer--a fixnum), then we can access its map directly without having to do the smi check. If we are storing an element in an array, and we know it is a smi, we don't need to emit a write barrier. So, type inference is another forward control-flow propagation algorithm, with a fixed-point iteration for phis in loop headers.
After type inference is run, each instruction in the whole graph is asked to canonicalize itself, which basically eliminates useless instructions: HToInt32 of a value with int32 representation, HCheckNonSmi of a value with non-smi type, etc.
deoptimization marks
When can you coerce undefined to an unboxed double? When you need a double for math, but you aren't going to eventually compare it to another double. The problem is that undefined coerces to NaN, but undefined == undefined and NaN != NaN. So, crankshaft marks any value used by a numeric compare as deoptimize-on-undefined. If the value is a phi, all connected phis must check for undefined, which can be a pretty big lose. But hey, that's JavaScript!
representation changes
Up to this point we've been dealing with values on a fairly high level, assuming that all of the definitions will be compatible with the uses. But as we chose to represent some temporaries as untagged values, there will need to be explicit conversions between representations -- hopefully not too many, but they will be needed. This pass inserts these representation changes.
This pass uses the truncating-to-int32 and deoptimize-on-undefined flags calculated in previous phases, to tell the changes what conditions they need to watch out for. Representation changes for phis happen just before branching to the block with the phi -- effectively, just before calling the block.
minus zero checks
The previous pass probably inserted a number of HChange instructions. For any HChange from int32 (which must be to tagged or double), Crankshaft traces dataflow backwards to mark the HChange(s) that produced the int32 as deoptimizing on negative zero. This allows parts of the graph to use fast int32 operations, while preserving the semantics of -0 should it appear, albeit more slowly (via a deoptimization).
stack check elimination
Loops need to be interruptable, and V8 does so by placing a stack check at the beginning of each loop iteration. If the runtime wants to interrupt a loop, it resets the stack limit of the process, and waits for the process's next stack check.
However if a call dominates all backward branches of a loop, then the loop can be interrupted by the stack check in the callee's prologue, so the stack check in the loop itself is unneeded and can be removed.
global value numbering: licm
I've been trying to get here for all this long page. Thanks to readers that have kept with it!
At this point, Hydrogen has served two of its three purposes: inlining and unboxing. The third is loop-invariant code motion (LICM) and common subexpression elimination (CSE). These important optimizations are performed by the perhaps misnamed global value numbering (GVN) pass.
LICM is about code motion: moving code out of hot loops. So what prevents an HInstruction from being moved? Two things: data dependencies, and side effects.
The LICM algorithm takes care of both of these. For every instruction in a loop, if it only depends on values defined outside the loop, and the side effects of the loop as a whole do not prevent the move, then LICM hoists the instruction to the loop header. If you do this in reverse post-order, you can hoist whole chains of expressions out of loops.
Every hydrogen instruction has a bitfield indicating the side effects that it causes, and a corresponding bitfield for the side effects that can affect it. In addition there is a flag indicating whether code motion is allowed for that instruction or not. These flags constitute a simple effects analysis -- if instruction B directly follows A, and A does not cause any side effects that B depends on, and B does not use the value from A, then B may be moved up before A.
Since the effects fields are simple bitfields, one can easily compute the side effects of a whole block by iterating over the instructions, doing a bitwise OR at each step. This is what LICM does -- it computes the side effects for the entire loop, and moves any instructions that it can to the loop header.
global value numbering: cse
Global value numbering, as implemented in V8, uses this technique in the opposite direction: instead of trying to hoist expressions up, it propagates them down the control-flow graph, trying to kill common subexpressions. A common subexpression is a Hydrogen value B that is "equal" in some sense to a previous instruction A, and whose value will not be affected by any side effects that occur on the control-flow paths between A and B. In this context, "value numbering" essentially means "define appropriate hash and equality functions and stick all the instructions you've seen in a hash table."
As GVN goes through the instructions of each block, in reverse-post-order, it puts them into this hash table (HValueMap). When GVN reaches an instruction that causes side effects, it flushes out the entries that depend on those side effects from the table. In that way, if ever it sees an instruction B that is equal to an instuction A in the table, GVN can remove B from its block, and replace every use of B with a use of A.
In standard SSA terminology you can consider instructions to be "definitions", because each instruction defines a value. Global value numbering works across basic blocks, hence the "global" in its name. Specifically, it eliminates equivalent definitions. One of the invariants of SSA is that "definitions dominate uses". So the part of the graph that should be searched for equivalent definitions is the part that is dominated by the original definition.
checked value replacement
In optimized code, accessing an array out of its bounds will cause a deoptimization. So the AST-to-Hydrogen translation will not emit a use of an index directly -- it inserts a bounds check, and has the array access use the result of the bounds check. But the purpose of this instruction is just to cause the side effect of deoptimization, and the resulting value is just a copy of the incoming index, which increases register allocation pressure for no reason. So now that code motion is complete, Crankshaft replaces uses of HBoundsCheck with the instruction that defines the index value, relying on the HBoundsCheck's position in the instruction stream to cause deopt as needed.
conclusions
In the end, the practical goals of Crankshaft are simple, and the optimizations are too, for the most part. Java people like to trot out all their gerundic compiler passes (see slide 7) and declare victory, and it is true that V8 and other modern JavaScript implementations will be beaten by the HotSpot JVM -- once it is allowed to warm up, of course. (V8's 5ms startup is particularly impressive, here.) But Crankshaft definitely has the basics, and throws in some range analysis to squeeze out a few more percent on top.
Finally, if you've gotten here, thanks again for reading this far. Comments and corrections are most welcome.
I have enjoyed being able to do this serious code reading, and some small bit of V8 hacking, as part of my work at Igalia. I think I'll have one more article about the platform-specific Lithium language, and its register allocator, and then see where I should move on from there. Happy hacking to all, and to all a good hack!
11 responses
Comments are closed.
I find these article very fascinating specifically because I don't understand them and they challenge me.
I would say keep up the great work, but I couldn't say if it's great or not. Instead I will say: keep up the great writing!
While this article is interesting, I think it would be much more interesting for others if you provided an example in Visual Basic. VB (Visual Basic) is used by many more people than Hydrogen language which hardly anyone has even heard of.
Keep up the good work however.
Great article! I do some compiler work and founding out about V8 is fascinating!
I must say that while the article itself was great, it was Wu Feng's comment that really made our day here at the V8 office.
Like many others, I also find these posts highly interesting and challenging. I can't say I understand most of it, but I found this interesting:
"To keep the big-O order of worklist operations down, you need a flag for each element indicating whether the element is already in the list. The bit should either be in the objects being traversed, or in a separate bitvector. In this particular case -- and in this case only, as far as I can tell -- there is no such bit, so the algorithm can take too much time, in certain cases."
So you mean here's an opportunity for yet another optimization? Did you do any tests on this? How often do you think it hits cases where the redundant phi count really explodes as more and more are eliminated?
Cheers,
Elvis
PS. Like for Erik above, Wu's VB comment really cracked me up as well :) DS.
Thanks for the notes, folks.
Elvis -- wonderful name! -- it's not a huge danger with that particular algorithm, but it should probably be rewritten to make steady progress forwards instead of adding phis to the worklist twice, even if it won't actually process a removed phi twice. You can check the algorithm yourself if you like: EliminateRedundantPhis.
Interesting article.
Wu Feng, I have conversed with my team here in Washington, and I can tell you definitively that v8 != VB.
Thank you,
Bill
Come on guys, still no VB (Visual Basic) examples? What gives?
Don't use .png images for the data structures where text would do as well; it simplifies and speeds up the page, better facilitating archival and search.
can you please put source file names next to the optimizations?
Have you looked at TurboFan lately? I came across this post:
http://v8project.blogspot.com/2015/07/digging-into-turbofan-jit.html
And since TurboFan is replacing Crankshaft, that means they are replacing Hydrogen and Lithium, correct?